
Search Entities with CluedIn Python SDK
In the latest release of CluedIn Python SDK, I added an improvement related to the GraphQL Search API; now is a good time to summarize how you can retrieve entities (golden records) from CluedIn with the help of GraphQL or CluedIn Python SDK that uses GraphQL anyway.
We will start with trivial UI options, dive deeper into GraphQL, and end up with a simple one-liner in Python to get the data you want from CluedIn.
Let's begin!
GraphQL Search API
First, CluedIn provides a powerful GraphQL API that is very helpful in almost every interaction with CluedIn (one of a few exceptions is Ingestion Endpoints that are not GraphQL). You can read about CluedIn GraphQL in the official documentation: documentation.cluedin.net/consume/graphql.
So, when you open the Consume section in your CluedIn instance, you will find a GraphQL playground where you can run GraphQL queries.
In my instance, I have some /Duck entities
(from the DuckTales).
To find them, I can run a query like this:
{
search(query:"+entityType:/Duck")
{
entries {
id
name
entityType
}
}
}
The query will return me the top 20 of the /Duck entities.
You can spot the query parameter, which tells the API to filter the response by a given Entity Type.
Also, you can see that I specified the entity properties I want to get in the payload: id, name, and entityType.
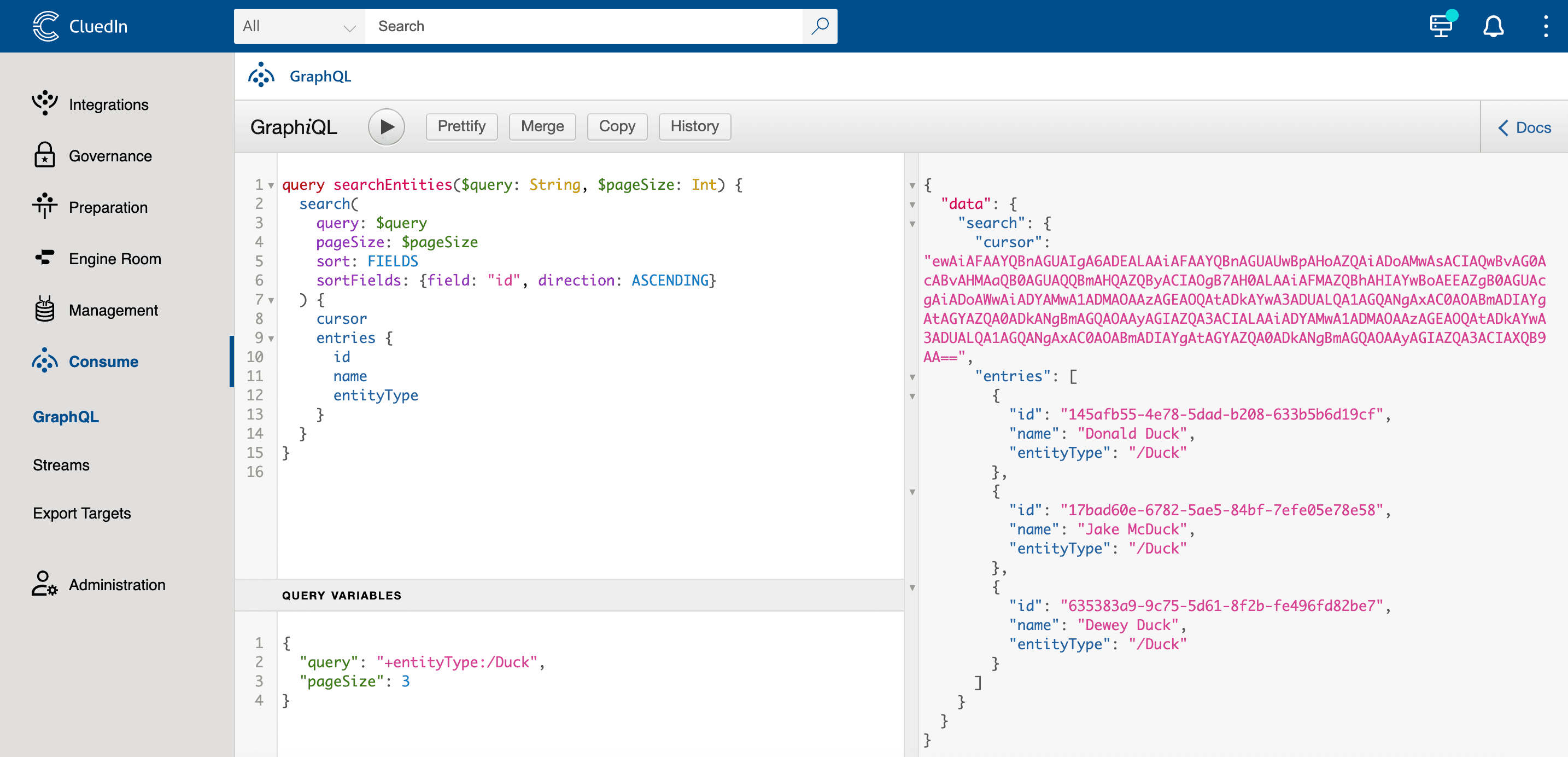
Now, we can sophisticate our query a little so that it will take parameters from the GraphQL variables:
query ($query: String, $pageSize: Int) {
search(
query: $query
pageSize: $pageSize
sort: FIELDS
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
Variables:
{
"query": "+entityType:/Duck",
"pageSize": 10000
}
Here are a few things to use in this query:
query ($query: String, $pageSize: Int)- as you can see, we defined a query with parameters. We can also give this query a name:query searchEntities($query: String, $pageSize: Int)sort: FIELDS sortFields: {field: "id", direction: ASCENDING}- it's important to sort by a unique field to get predictable results when you page data.cursor- we ask CluedIn to return a special value that we can pass to our next query to get the next page of results."pageSize": 10000- By default, the page size is 20, so if you have millions of entities, you will get only the first20. It's a good practice to set the page size to the maximum allowed value -10000, but there are situations when you only want to get a few entities from the top, and a query with a smaller page size will be faster.
CluedIn Python SDK
You can use any programming language to send a GraphQL request to CluedIn and get the data back. Let's explore how you can do it in Python.
First of all, you will need to install the latest version of CluedIn Python SDK:
%pip install cluedin
Let's import it then together with Pandas (we will use Pandas to load data in DataFrames):
import pandas as pd
import cluedin
You need an API token; you can copy or create a new one by going to "API Tokens" under "Administration" in CluedIn.
Now, in my case, CluedIn is installed at https://foobar.klimenko.dk/,
so I need to initialize a context for my CluedIn instance by providing org_name (foobar), domain (klimenko.dk), and the access_token (the one you copied from CluedIn UI):
ctx = cluedin.Context.from_dict({
'domain': 'klimenko.dk',
'org_name': 'foobar',
'access_token': '{paste_your_token_here}'
})
Remember the GraphQL query we ran from CluedIn UI? We can now run it from the Python code:
query = """
query searchEntities($query: String, $pageSize: Int) {
search(
query: $query
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 3
}
cluedin.gql.gql(ctx, query=query, variables=variables)
The result is top three entities (because we use the page size = 3 for demo purpose), and we also get a cursor that we can use to get the next page:
{'data': {'search': {'cursor': 'ewAiAFAAYQBnAGUAIgA6ADEALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIALAAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIAXQB9AA==',
'entries': [{'id': '145afb55-4e78-5dad-b208-633b5b6d19cf',
'name': 'Donald Duck',
'entityType': '/Duck'},
{'id': '17bad60e-6782-5ae5-84bf-7efe05e78e58',
'name': 'Jake McDuck',
'entityType': '/Duck'},
{'id': '635383a9-9c75-5d61-8f2b-fe496fd82be7',
'name': 'Dewey Duck',
'entityType': '/Duck'}]}}}
Now, we can change our code a little to pass the cursor as a parameter:
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
cursor: $cursor
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 3
'cursor': 'ewAiAFAAYQBnAGUAIgA6ADEALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIALAAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIAXQB9AA=='
}
cluedin.gql.gql(ctx, query=query, variables=variables)
The result is the next three entities:
{'data': {'search': {'cursor': 'ewAiAFAAYQBnAGUAIgA6ADIALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADkAMwBiADkAMgA4ADMANQAtADkANgBmADIALQA1ADYAYQA5AC0AOQA4AGMAMAAtAGMAOAA0ADgAMgAzADYANQAyADEAYQA5ACIALAAiADkAMwBiADkAMgA4ADMANQAtADkANgBmADIALQA1ADYAYQA5AC0AOQA4AGMAMAAtAGMAOAA0ADgAMgAzADYANQAyADEAYQA5ACIAXQB9AA==',
'entries': [{'id': '6ae43a44-81b4-5fd7-9c7b-47cb24d407ea',
'name': 'Angus McDuck',
'entityType': '/Duck'},
{'id': '9353b703-13d8-59a1-886c-f40b95283c06',
'name': 'Hortense McDuck',
'entityType': '/Duck'},
{'id': '93b92835-96f2-56a9-98c0-c848236521a9',
'name': 'Matilda McDuck',
'entityType': '/Duck'}]}}}
You get the idea.
But what if you want to avoid manually passing a new cursor to every new call?
Just use the cluedin.gql.entries method, and it will return you
a Generator
that you can convert to a list or just iterate as you wish:
...
# this is where you need a smaller page size
# if you don't want to iterate to the end
variables = {
'query': '+entityType:/Duck',
'pageSize': 2
}
generator = cluedin.gql.entries(ctx, query=query, variables=variables)
print(next(generator))
print(next(generator))
Result:
{'id': '145afb55-4e78-5dad-b208-633b5b6d19cf', 'name': 'Donald Duck', 'entityType': '/Duck'}
{'id': '17bad60e-6782-5ae5-84bf-7efe05e78e58', 'name': 'Jake McDuck', 'entityType': '/Duck'}
Or you can load all entities in a DataFrame, in this case,
it makes sense using the maximum page size (10000) to reduce the number of calls to the server:
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
cursor: $cursor
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 10_000
}
print(pd.DataFrame(cluedin.gql.entries(ctx, query=query, variables=variables)))
Result:
id name entityType
0 145afb55-4e78-5dad-b208-633b5b6d19cf Donald Duck /Duck
1 17bad60e-6782-5ae5-84bf-7efe05e78e58 Jake McDuck /Duck
2 635383a9-9c75-5d61-8f2b-fe496fd82be7 Dewey Duck /Duck
3 6ae43a44-81b4-5fd7-9c7b-47cb24d407ea Angus McDuck /Duck
4 9353b703-13d8-59a1-886c-f40b95283c06 Hortense McDuck /Duck
5 93b92835-96f2-56a9-98c0-c848236521a9 Matilda McDuck /Duck
6 a388a77d-7d43-51d1-87b2-efb4f854b5ad Fergus McDuck /Duck
7 b2fb05cb-e806-5088-955b-2ff3f9261236 Scrooge McDuck /Duck
8 b8fc5baf-b679-5e26-abb5-50ca77467992 Huey Duck /Duck
9 cd8fe1dd-5637-5037-931e-f8bf1a15c0b4 Della Duck /Duck
10 f5bf5d66-5698-515a-800e-9d778d916dcd Louie Duck /Duck
Starting from CluedIn Python SDK 2.5.0, you can shrink the code above to one line and get almost the same result. The difference is that it will also return you all codes and properties of entities, but this is what most users do anyway, and you don't have to copy and paste the same GraphQL query every time you want to query some data:
# this will return all the queried entities with all properties and codes
print(pd.DataFrame(cluedin.gql.search(ctx, '+entityType:/Duck')))
Finally, if you only want a subset of data, you can use the itertools.islice,
but then remember to set a smaller page_size to not query more data than you need:
from itertools import islice
# gets a generaror that queries entities from the server by three
gen = cluedin.gql.search(ctx, '+entityType:/Duck', page_size=3)
# wrap in an iterator that stops after three iterations
iter = islice(gen, 3)
# convert to DataFrame
df = pd.DataFrame(iter)
print(df)
Or simply:
pd.DataFrame(itertools.islice(cluedin.gql.search(ctx, '+entityType:/Duck', 3), 3))