
Using Pandas, Polars, and DuckDB for the same task
 (image source: https://huggingface.co/alvarobartt/ghibli-characters-flux-lora)
(image source: https://huggingface.co/alvarobartt/ghibli-characters-flux-lora)
As a regular Pandas user, I am usually satisfied with its performance. It can handle millions of records in minutes on my humble laptop, and I'm okay with waiting. However, new fancy tools are coming out, and I am curious to explore them.
I usually use IMDb datasets for testing and demos, so today, I undertook a familiar routine: loading each TSV (tab-separated values) file in a directory and saving it as Parquet. The only difference was that I did it with three different tools: Pandas, Polars, and DuckDB.
The IMDb's TSVs have their specifics:
- While they are mostly like normal CSV files, the separator is a tab instead of a comma.
- Numeric values (years) are mixed with '\N' values, which we can replace with nulls or change the columns' types to string (I go with the second option).
- Double quotes appear in column values, so we need to ignore them explicitly.
Pandas
I'm starting with Pandas as the most known tool. A simple version of the code looks like this:
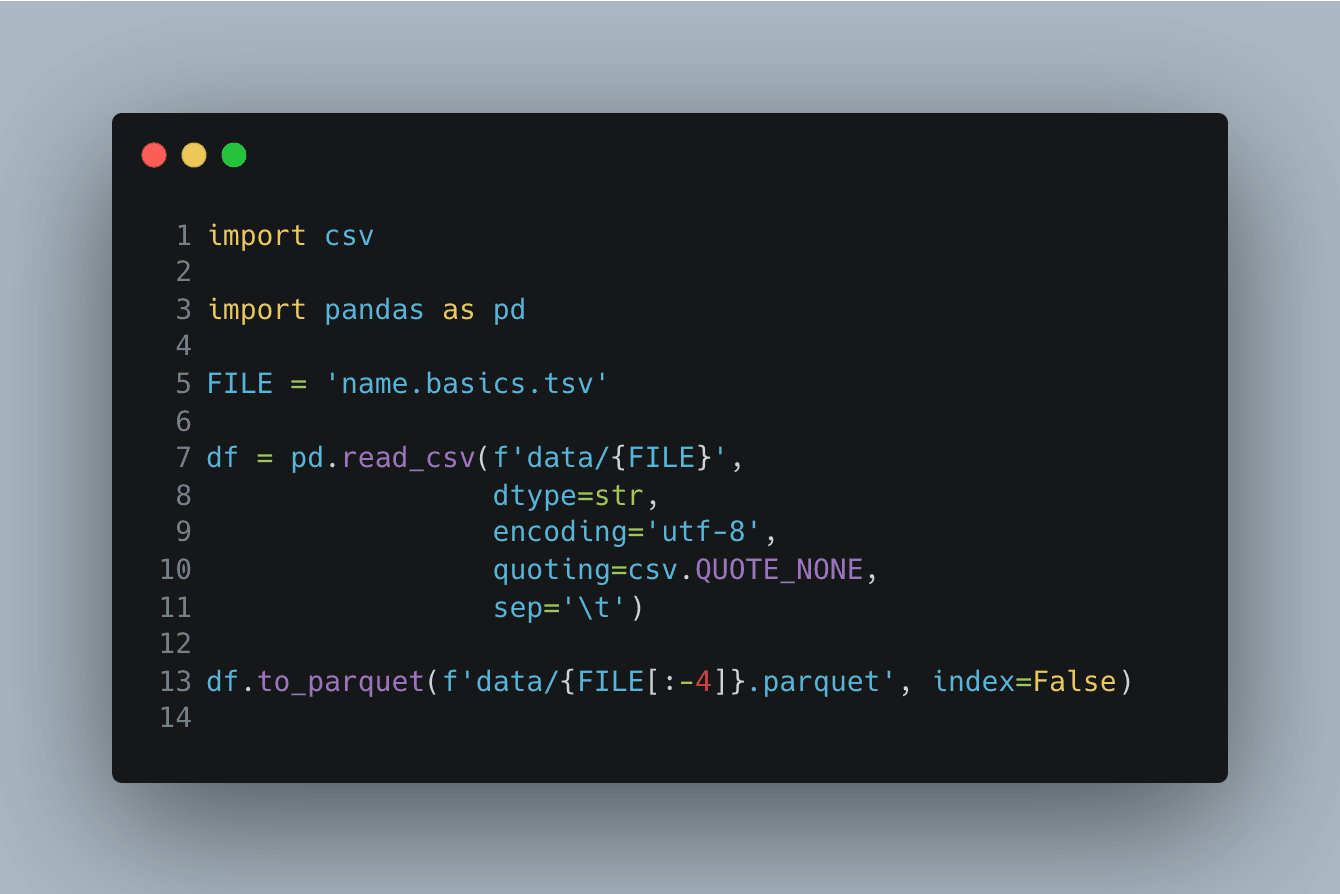
The names.basic.tsv contains 13.774.705 rows, and it takes 15-20 seconds
for my four-year-old Apple MacBook M1 to run the script.
Polars
Now, let's take a look at Polars.
The Polars API is intuitive after Pandas, and I had no problems using it.
The code appeared a little bit longer because there was no dtype parameter in the read_csv
method to override all column types at once, but this is not a problem:
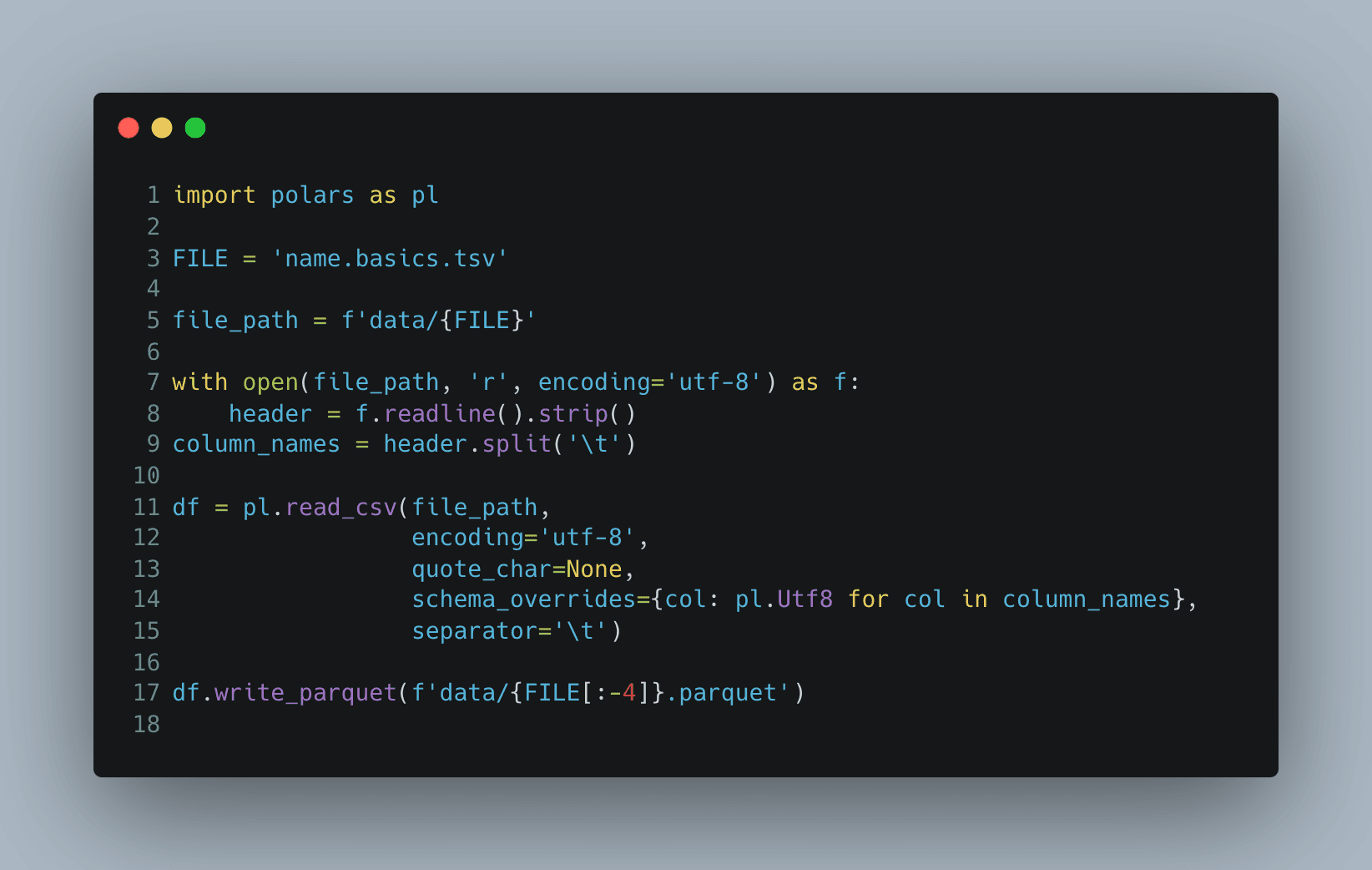
This code runs for 14-15 seconds.
DuckDB
With DuckDB, you can use SQL:
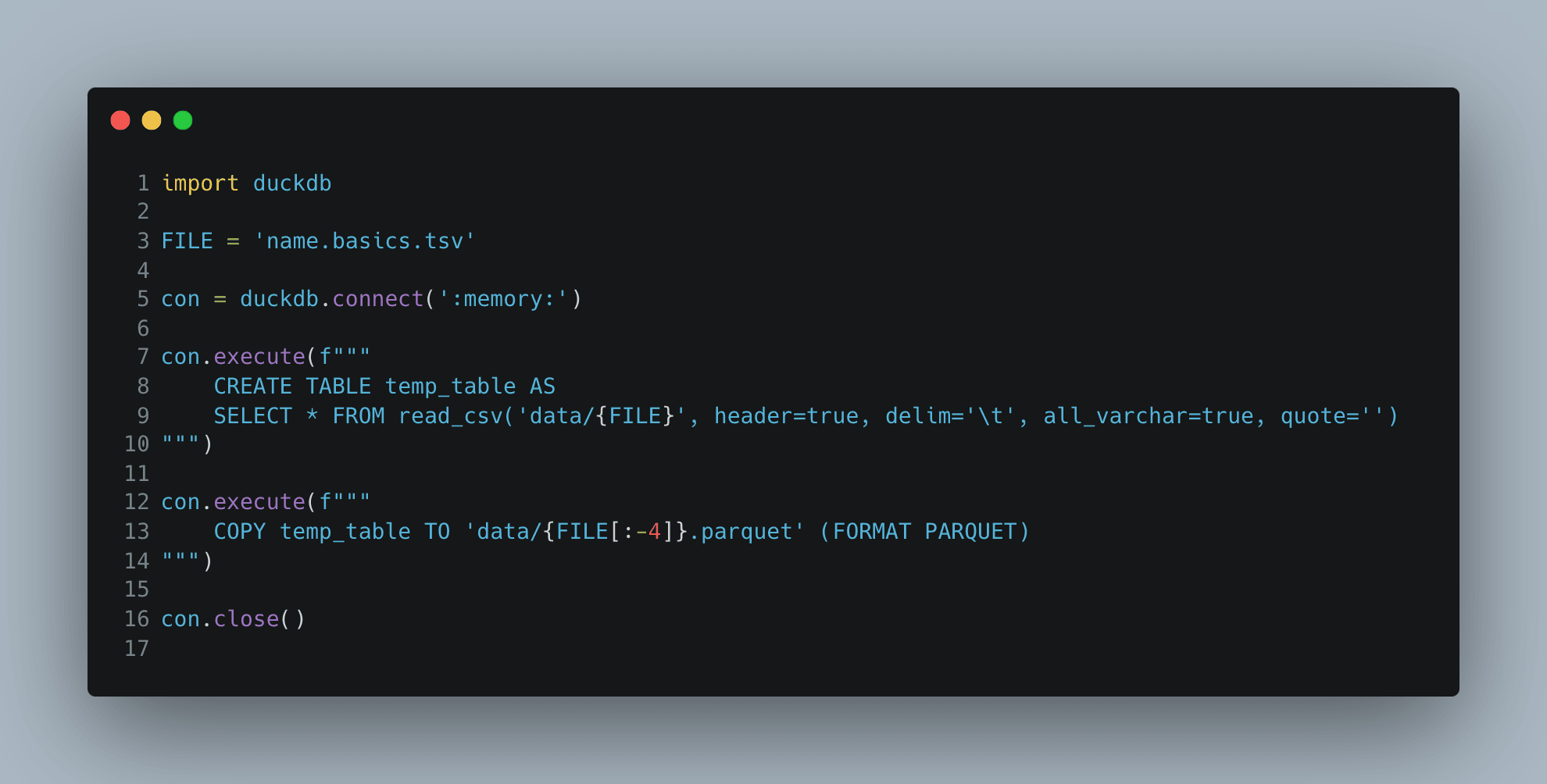
Alternatively, you can use the SDK methods:
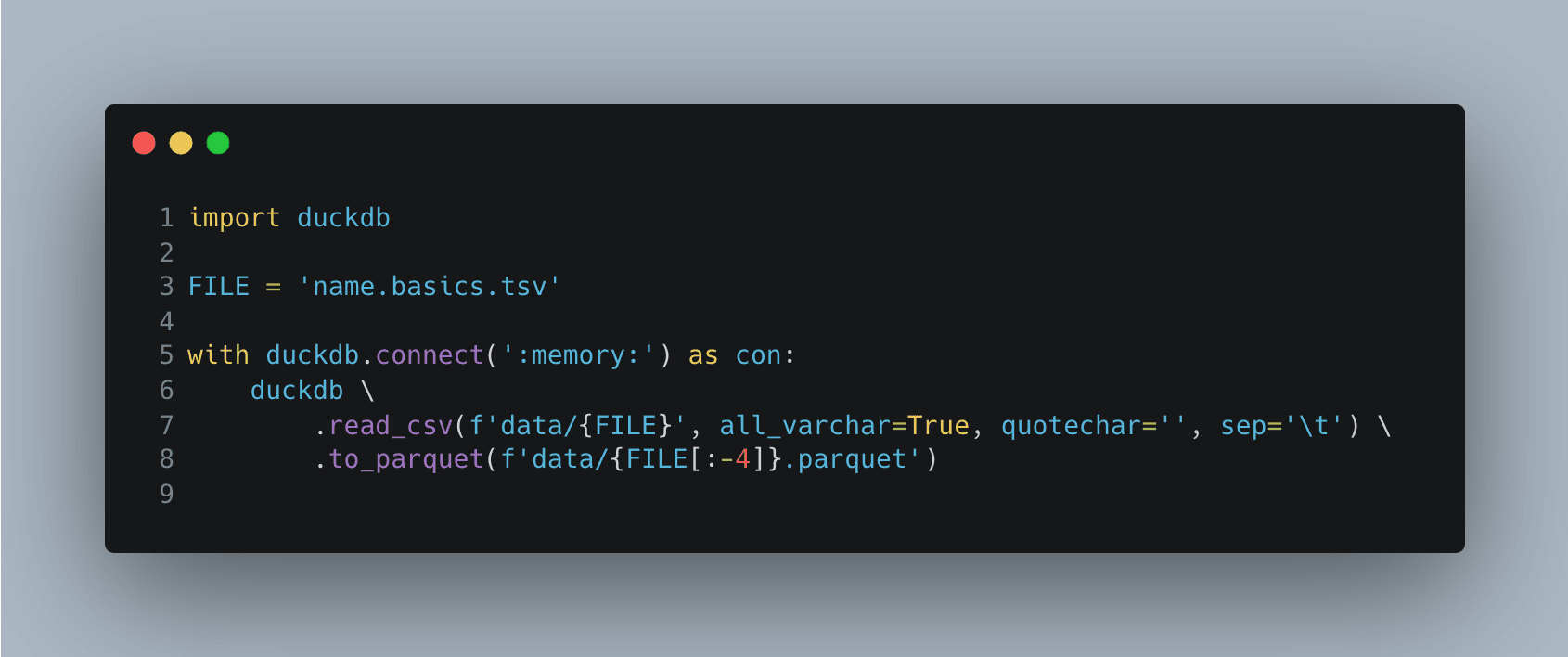
In the last example, the table is not created: duckdb.read_csv
returns a lazy object that is only iterated when we call .to_parquet,
which makes the execution even faster: around six seconds
if we create a table and four seconds if we don't.
The DuckDB's API is sometimes surprising. For example, read_csv
has sep and delim parameters for the same thing,
which is confusing when you scroll through the list of the method's parameters,
especially because the Python SDK has no docstrings. Also, when something goes wrong,
you see an output like this:
delimiter = (Set By User)
So you have sep, delim, but it's called delimiter in the error message.
But there's nothing to complain about seriously — the API is rich, and the tool works great.
Loading all IMDb datasets
In the next step, I prepared scripts to load each IMDb TSV file in a directory and save them to Parquet. I'm not going to overload this article with code, but you can find the scripts here: https://github.com/romaklimenko/imdb
The performance results were surprising. I expected Polars to do the job faster than Pandas, but it was significantly slower. The average running times for each script are:
- Pandas:
196seconds - Polars:
257seconds - DuckDB:
46seconds
DuckDB is way ahead of the others, but Pandas and Polars win and lose in different categories.
For example, title.principals.tsv has 87.769.634 rows:
- Pandas: load TSV -
49seconds, write to Parquet -32seconds. - Polars: load TSV -
140seconds, write to Parquet -10seconds.
But take title.basics.tsv, which is 11.054.773 rows:
- Pandas: load TSV -
14seconds, write to Parquet -6seconds. - Polars: load TSV -
6seconds, write to Parquet -4seconds.
Conclusion
Benchmarking tools on a single scenario is a thankless task. Sure, there are cases when Polars are faster than Pandas: https://duckdblabs.github.io/db-benchmark/, but the difference is not so obvious in "small" datasets of several millions of records.
I hope these products find their niche, as Pandas' and Polars' APIs are similar.
DuckDB shows impressive performance and solves many problems, whereas I'd have to run a database server otherwise. Its API is not very polished yet, but I can tolerate it for its good features.
I'm looking forward to using these new tools for my daily tasks.