
Eksport af data fra Databricks eller Microsoft Fabric til CluedIn
I den forrige artikel indlæste vi data fra CluedIn til Databricks ved hjælp af cluedin-biblioteket og en Jupyter-notebook. I denne artikel gør vi det modsatte: vi indlæser data fra Databricks til CluedIn.
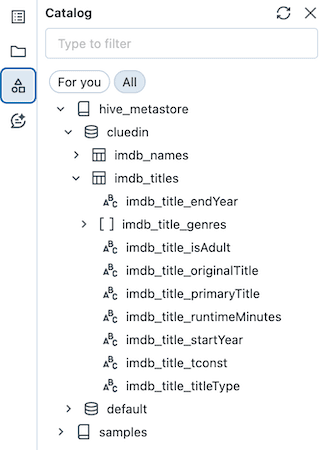
Lad os starte med et simpelt eksempel. Vi har en tabel ved navn imdb_titles i Databricks med 601.222 rækker:
CluedIn
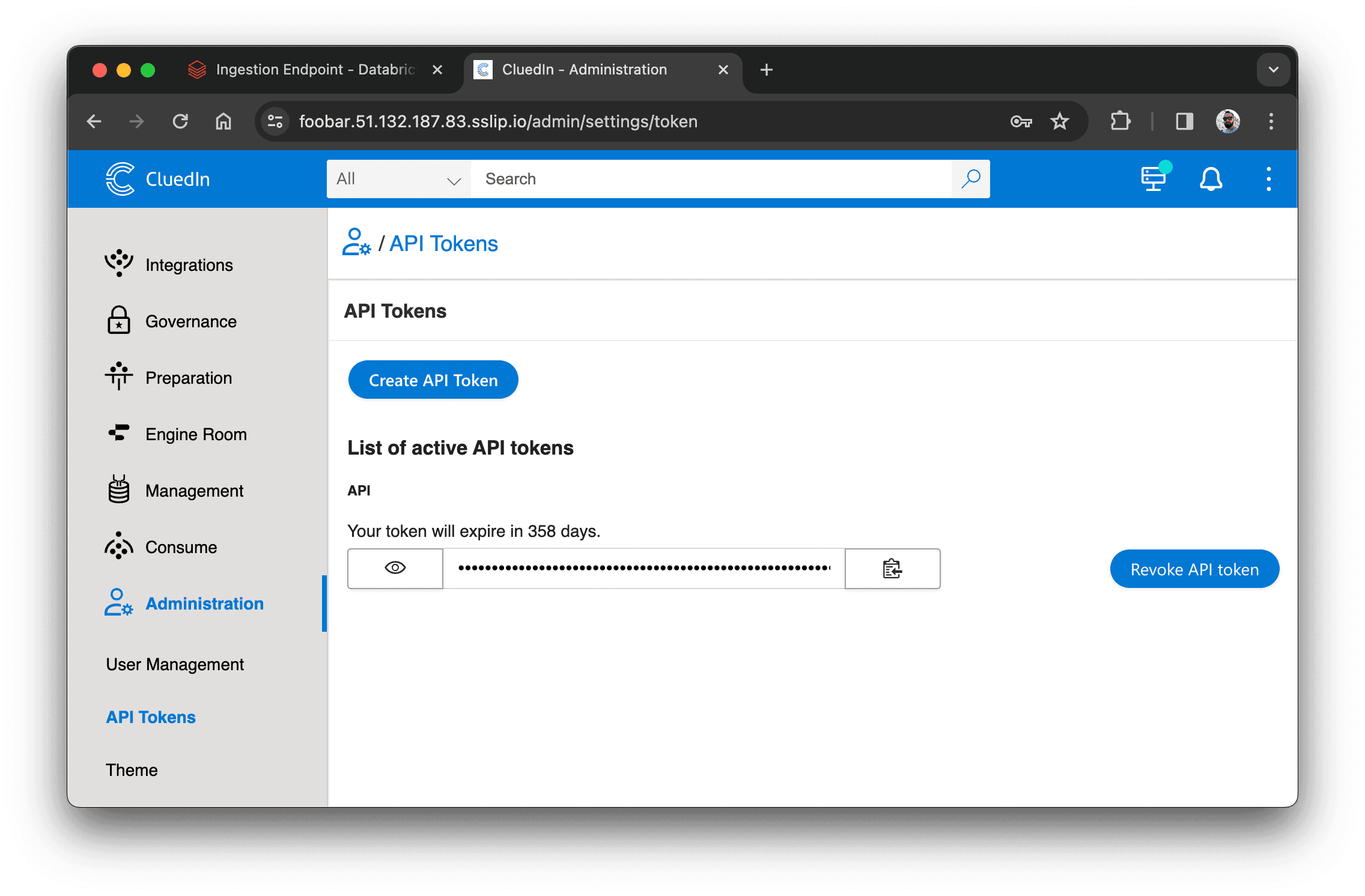
Vi vil indlæse disse data i CluedIn. For at gøre det skal vi oprette et API-token i CluedIn. Gå til Administration > API Tokens og opret et nyt token:
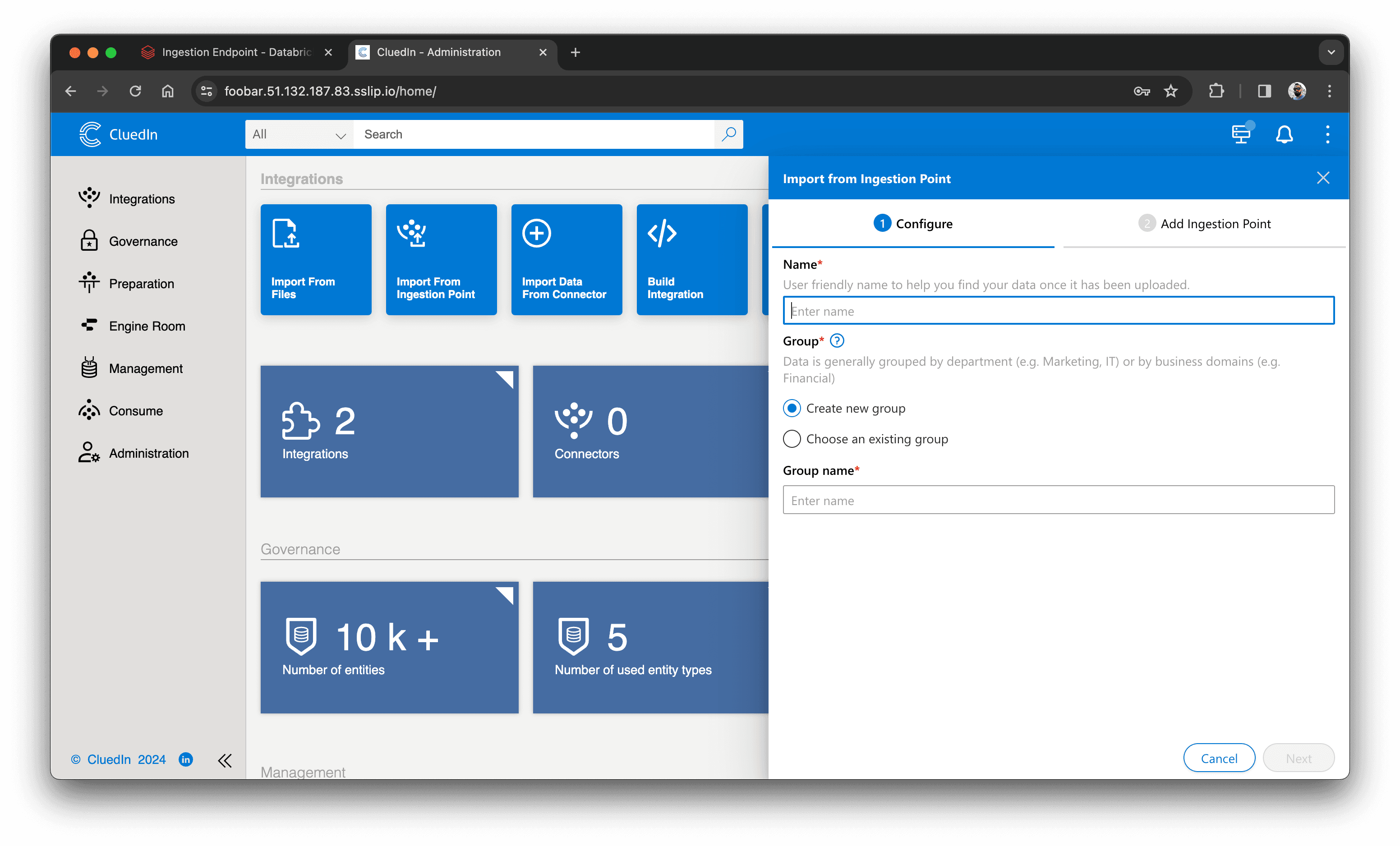
Derefter opretter vi et endpoint i CluedIn. Fra CluedIns hovedside klikker du på "Import From Ingestion Endpoint" og opretter et nyt endpoint. Du skal angive endpointets navn, gruppenavn og vælge entity type:
Når du har oprettet endpointet, finder du dets URL i sektionen "View Instructions":
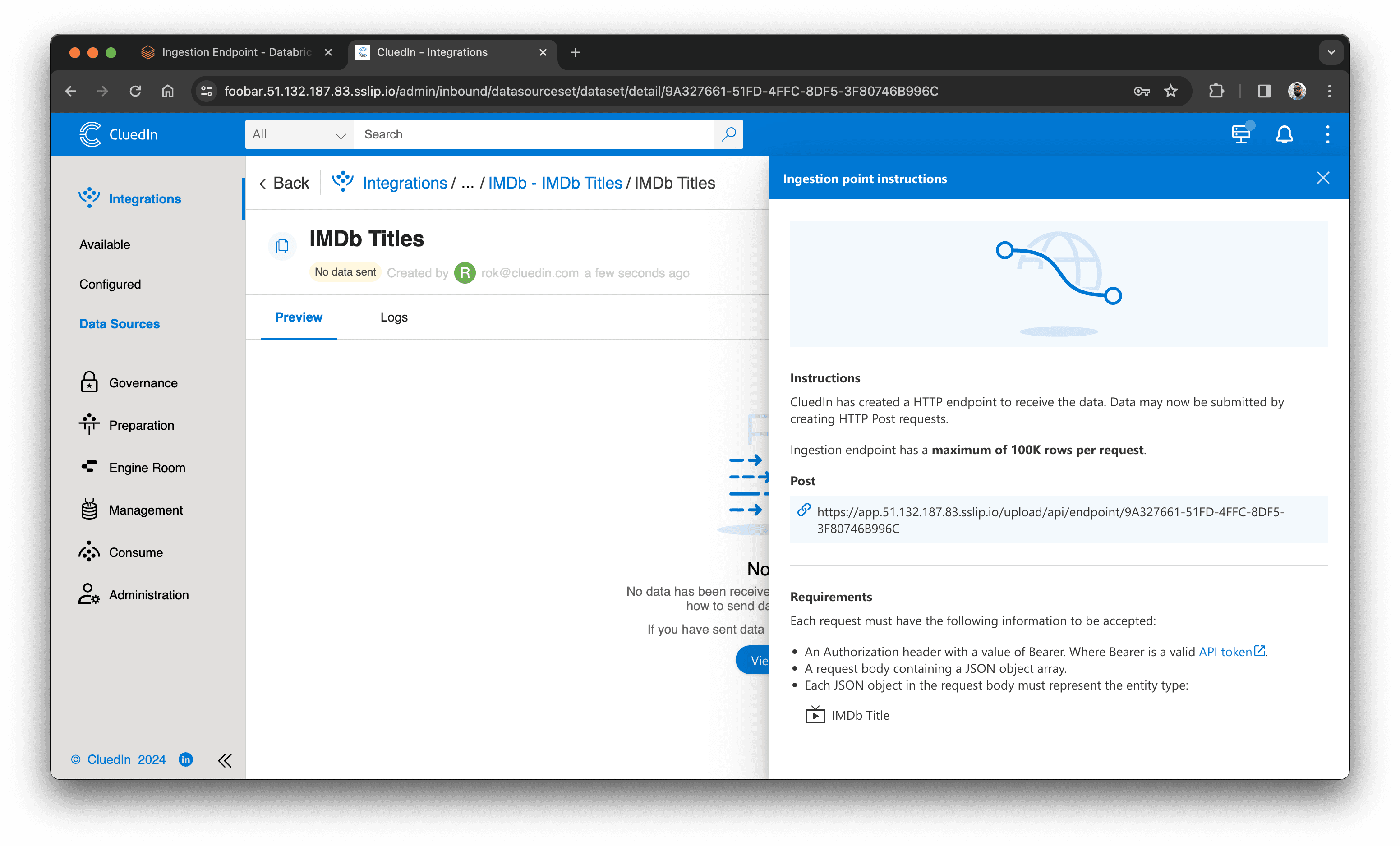
Vi er klar til at indlæse data i CluedIn. Nu er det tid til at konfigurere Databricks.
Databricks
I Databricks opretter vi en Jupyter-notebook og installerer cluedin-biblioteket:
%pip install cluedin
Derefter importerer vi cluedin-biblioteket og opretter et CluedIn context-objekt:
import requests
import cluedin
ctx = cluedin.Context.from_dict(
{
"domain": "51.132.187.83.sslip.io",
"org_name": "foobar",
"access_token": "(your token)",
}
)
ENDPOINT_URL = "https://app.51.132.187.83.sslip.io/upload/api/endpoint/9A327661-51FD-4FFC-8DF5-3F80746B996C"
DELAY_SECONDS = 5
BATCH_SIZE = 100_000
I vores eksempel er URL'en til vores CluedIn-instans https://foobar.51.132.187.83.sslip.io/, så domænet er 51.132.187.83.sslip.io og organisationsnavnet er foobar. Access token er det, vi oprettede tidligere.
Dernæst henter vi data fra Databricks og sender dem til CluedIn.
Her er en simpel metode til at vælge alle rækker fra en tabel og returnere dem én ad gangen:
from pyspark.sql import SparkSession
def get_rows():
spark = SparkSession.builder.getOrCreate()
imdb_names_df = spark.sql("SELECT * FROM hive_metastore.cluedin.imdb_titles")
for row in imdb_names_df.collect():
yield row.asDict()
Dernæst opretter vi en metode, der sender en batch af rækker til CluedIn:
import time
from datetime import timedelta
def post_batch(ctx, batch):
response = requests.post(
url=ENDPOINT_URL,
json=batch,
headers={"Authorization": f"Bearer {ctx.access_token}"},
timeout=60,
)
time.sleep(DELAY_SECONDS)
return response
def print_response(start, iteration_start, response) -> None:
time_from_start = timedelta(seconds=time.time() - start)
time_from_iteration_start = timedelta(
seconds=time.time() - iteration_start)
time_stamp = f'{time_from_start} {time_from_iteration_start}'
print(f'{time_stamp}: {response.status_code} {response.json()}\n')
print_response er en hjælpemetode, der udskriver svarets statuskode og svarindholdet.
Til sidst itererer vi over rækkerne og sender dem til CluedIn. Bemærk at vi sender rækkerne i batches af BATCH_SIZE rækker. DELAY_SECONDS er antallet af sekunder, vi venter mellem batches.
Vi skal dog først sende en lille batch af rækker for at konfigurere mapping på CluedIn-siden. Vi sender ti rækker. For at gøre det tilføjer vi følgende linjer i koden nedenfor:
if i >= 10:
break
Her er koden, der sender rækkerne til CluedIn:
batch = []
batch_count = 0
start = time.time()
iteration_start = start
for i, row in enumerate(get_rows()):
if i >= 10:
break
batch.append(row)
if len(batch) >= BATCH_SIZE:
batch_count += 1
print(f'posting batch #{batch_count:_} ({len(batch):_} rows)')
response = post_batch(ctx, batch)
print_response(start, iteration_start, response)
iteration_start = time.time()
batch = []
if len(batch) > 0:
batch_count += 1
print(f'posting batch #{batch_count:_} ({len(batch):_} rows)')
response = post_batch(ctx, batch)
print_response(start, iteration_start, response)
iteration_start = time.time()
print(f'posted {(i + 1):_} rows')
Når vi kører koden, bør vi se ti rækker i CluedIn:
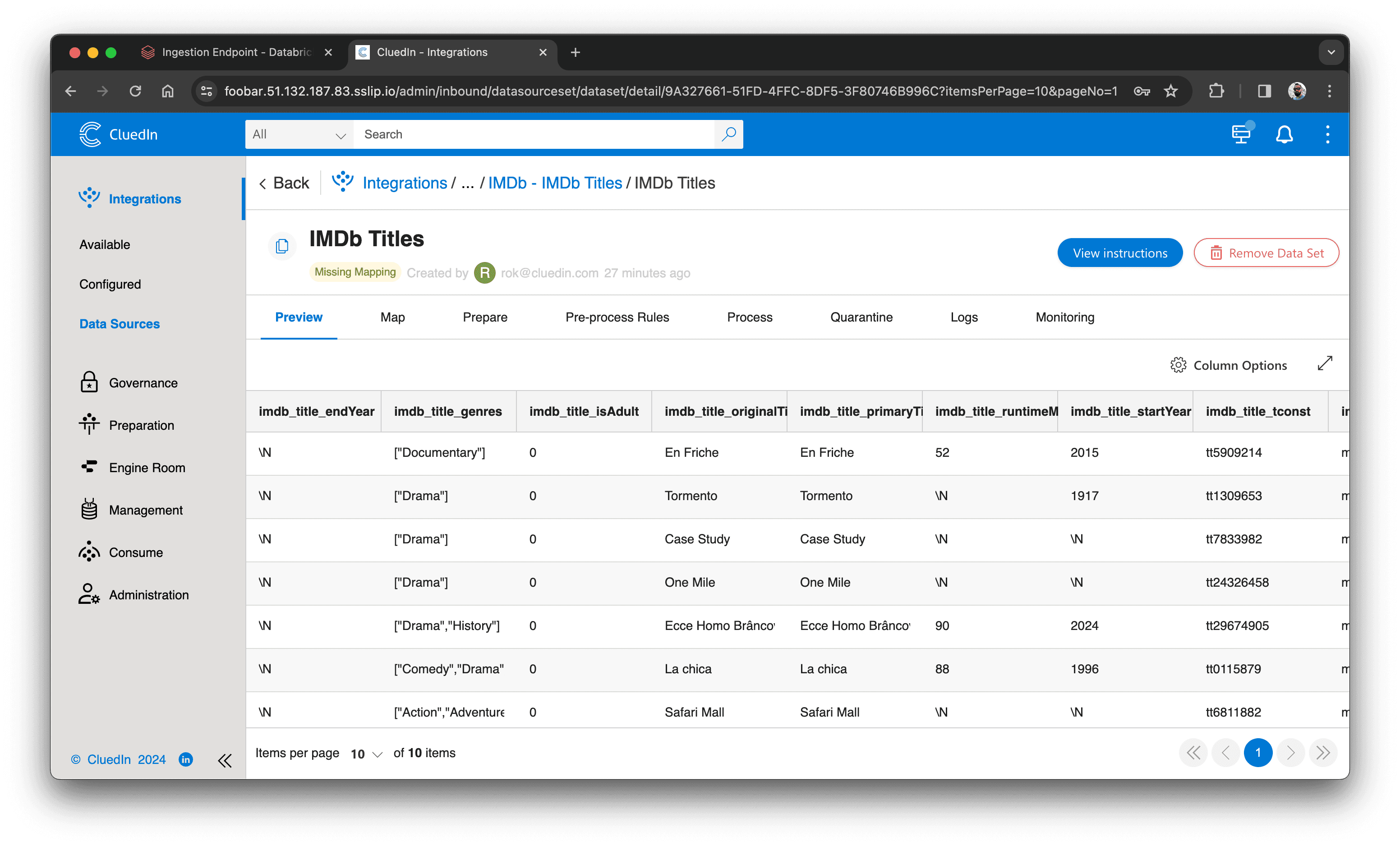
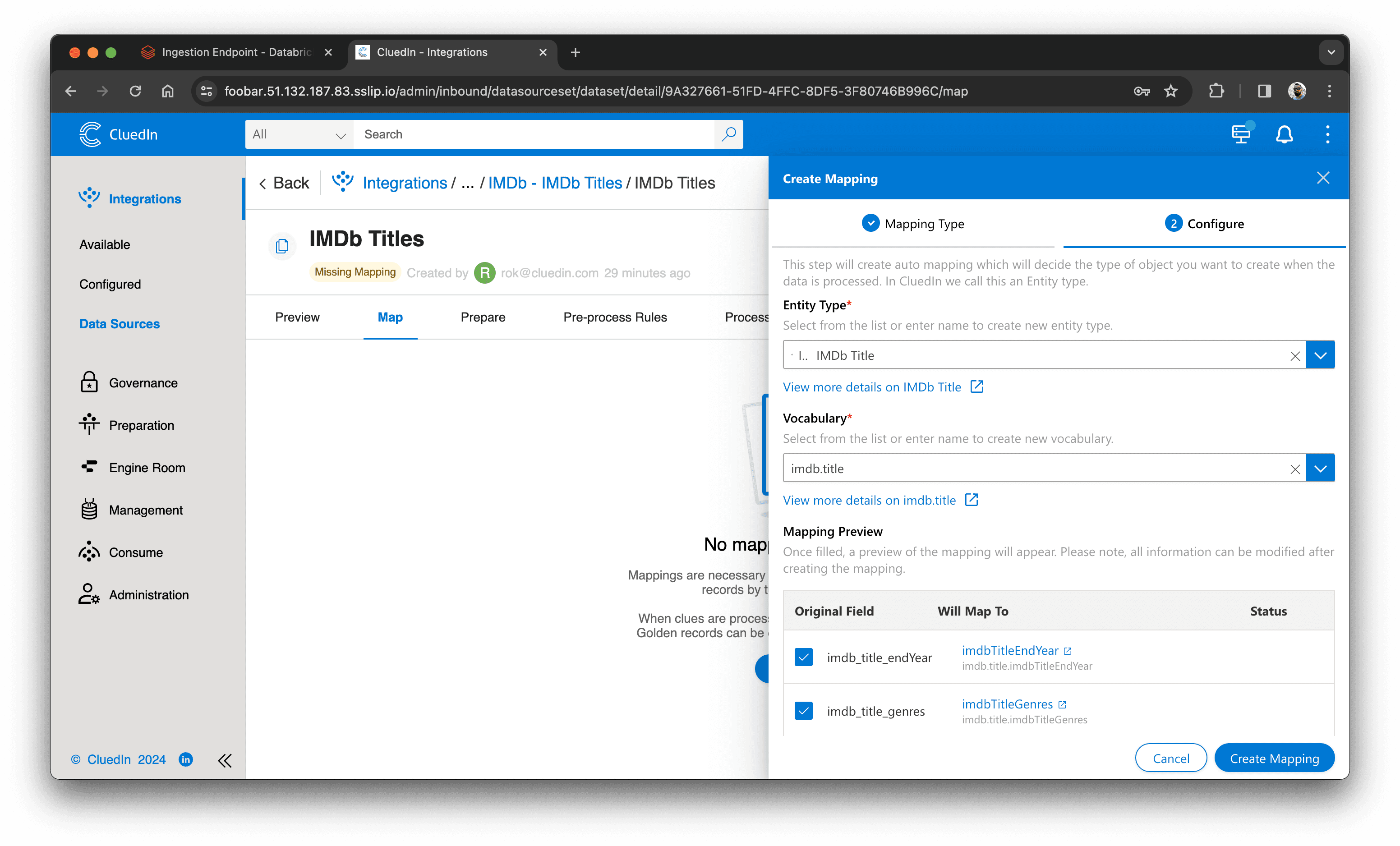
Derefter opretter vi en automatisk mapping i Map-fanen:
- Klik på "Add Mapping".
- Vælg "Auto Mapping" og "Next".
- Sørg for at entity type er valgt, eller skriv et nyt entity type-navn og klik "Create".
- Skriv det nye vocabulary-navn, f.eks.
imdb.title, og klik "Create". - Klik "Create Mapping".
- Klik "Edit Mapping".
- I fanen "Map Entity" vælger du den property, der bruges som entity-navn, og den property, der bruges til origin entity code:
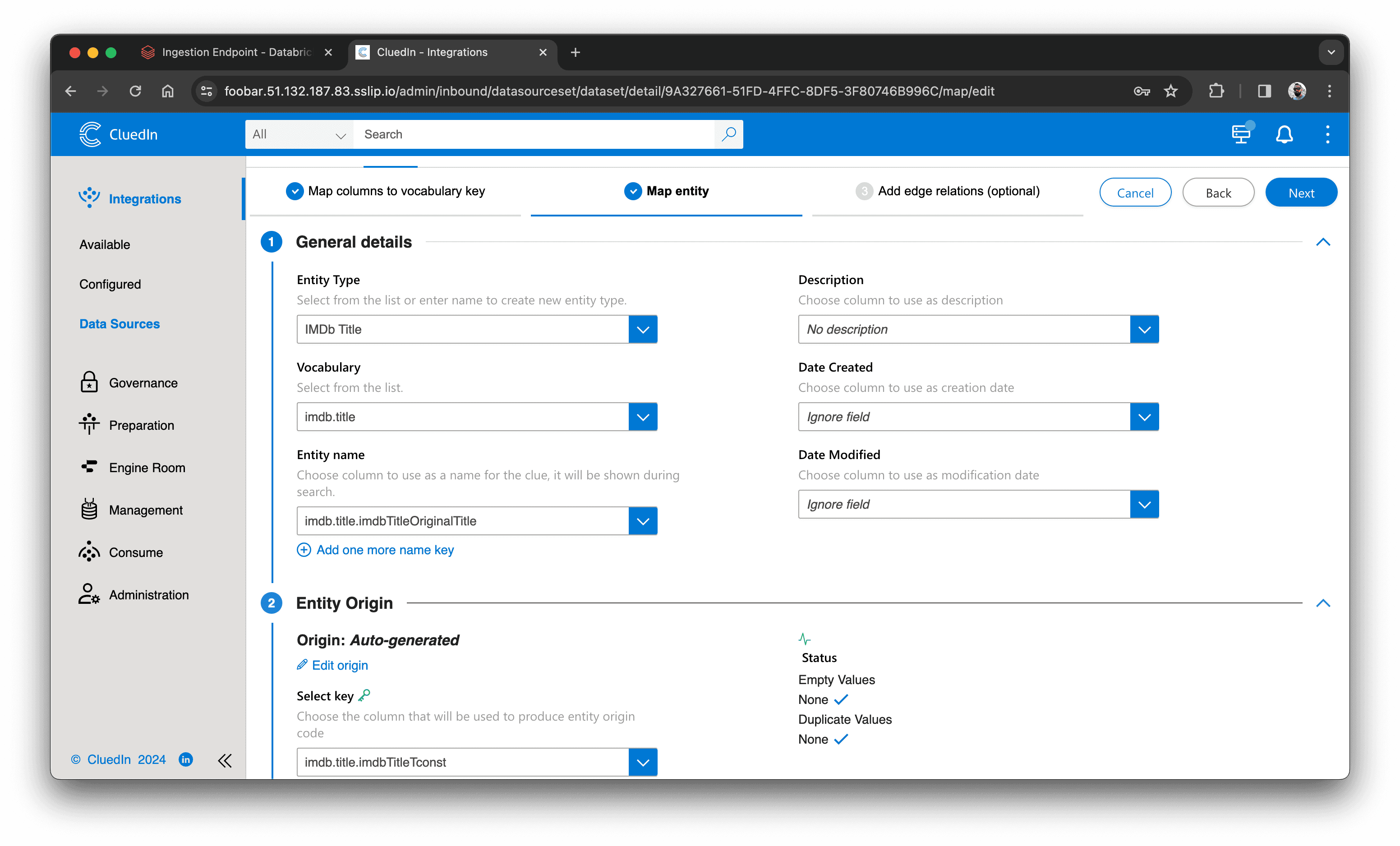
- Klik "Next" og klik "Finish".
- I fanen "Process" aktiverer du "Auto submission" og klikker derefter på "Switch to Bridge Mode":
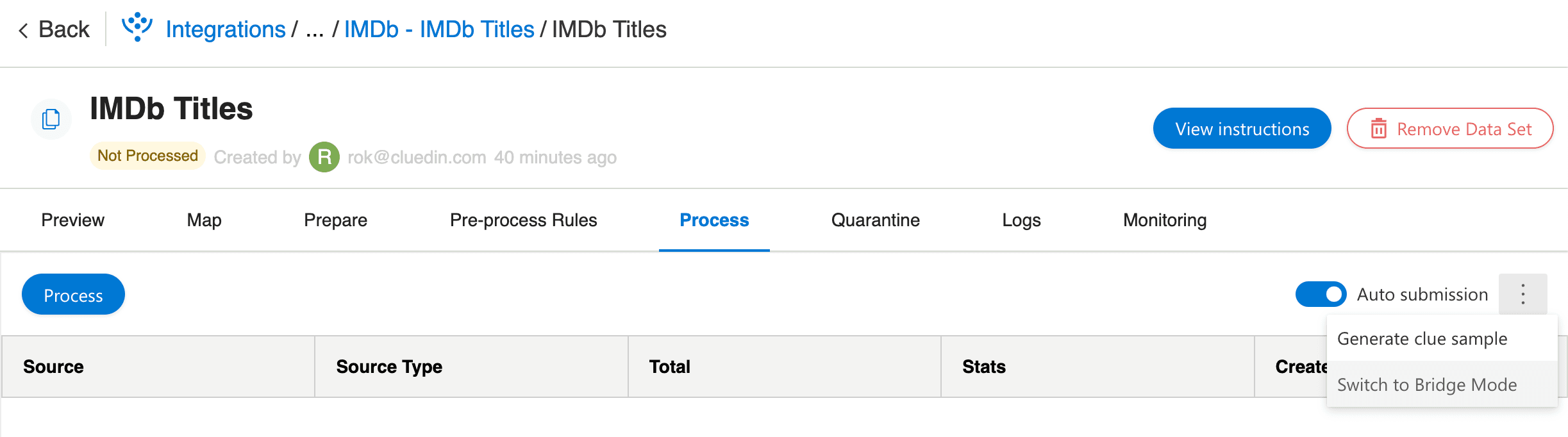
- Når du har fulgt instruktionerne, kan du fjerne eller udkommentere disse linjer i notebooken og køre den igen:
if i >= 10:
break
Alle tabelrækker vil blive sendt til CluedIn. Outputtet i notebooken vil se sådan ud:
0:00:13.398879 0:00:13.398889: 200 {'success': True, 'warning': False, 'error': False}
posting batch #2 (100_000 rows)
0:00:22.021498 0:00:08.622231: 200 {'success': True, 'warning': False, 'error': False}
posting batch #3 (100_000 rows)
0:00:30.709844 0:00:08.687518: 200 {'success': True, 'warning': False, 'error': False}
posting batch #4 (100_000 rows)
0:00:40.026708 0:00:09.316675: 200 {'success': True, 'warning': False, 'error': False}
posting batch #5 (100_000 rows)
0:00:48.530380 0:00:08.503460: 200 {'success': True, 'warning': False, 'error': False}
posting batch #6 (100_000 rows)
0:00:57.116517 0:00:08.585930: 200 {'success': True, 'warning': False, 'error': False}
posting batch #7 (1_222 rows)
0:01:02.769714 0:00:05.652984: 200 {'success': True, 'warning': False, 'error': False}
posted 601_222 rows
Giv CluedIn lidt tid til at behandle dataene, og du bør se 601.222 rækker i CluedIn.
Den samme tilgang virker ikke kun med Databricks, men også med enhver anden datakilde. Du skal blot ændre get_rows-metoden til at hente data fra din kilde.