
Søg efter entiteter med CluedIn Python SDK
I den seneste udgave af CluedIn Python SDK tilføjede jeg en forbedring relateret til GraphQL Search API; nu er det et godt tidspunkt at opsummere, hvordan du kan hente entiteter (golden records) fra CluedIn ved hjælp af GraphQL eller CluedIn Python SDK, der alligevel bruger GraphQL.
Vi starter med trivielle UI-muligheder, dykker dybere ned i GraphQL og ender med en simpel one-liner i Python til at hente de data, du ønsker fra CluedIn.
Lad os begynde!
GraphQL Search API
Først og fremmest tilbyder CluedIn et kraftfuldt GraphQL API, der er meget nyttigt i næsten enhver interaktion med CluedIn (en af de få undtagelser er Ingestion Endpoints, der ikke er GraphQL). Du kan læse om CluedIn GraphQL i den officielle dokumentation: documentation.cluedin.net/consume/graphql.
Når du åbner Consume-sektionen i din CluedIn-instans, finder du en GraphQL playground, hvor du kan køre GraphQL-forespørgsler.
I min instans har jeg nogle /Duck-entiteter (fra DuckTales). For at finde dem kan jeg køre en forespørgsel som denne:
{
search(query:"+entityType:/Duck")
{
entries {
id
name
entityType
}
}
}
Forespørgslen returnerer top 20 af /Duck-entiteterne. Du kan se query-parameteren, som fortæller API'et at filtrere svaret efter en given Entity Type. Du kan også se, at jeg angav de entity-egenskaber, jeg vil have i payloaden: id, name og entityType.
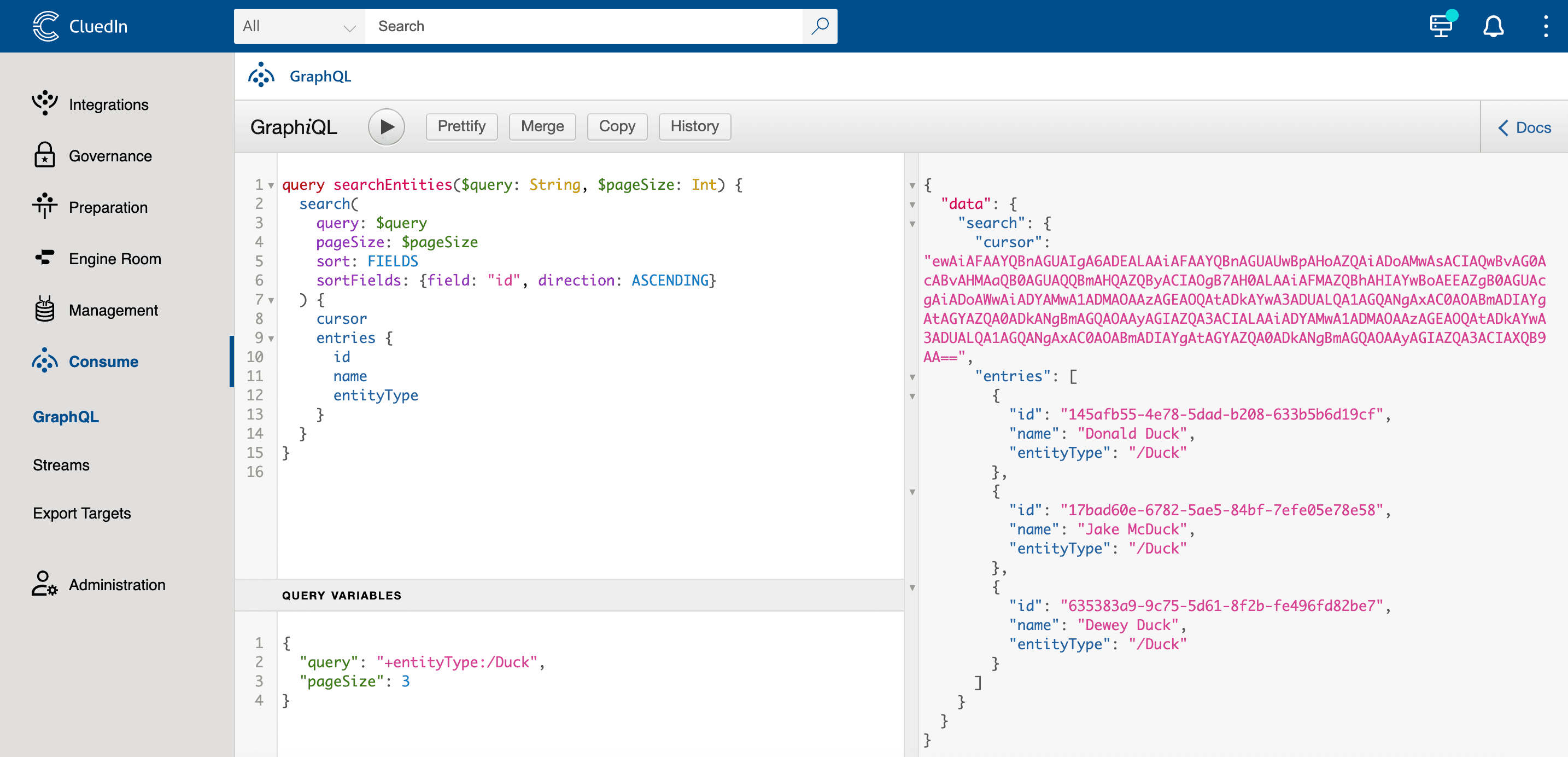
Nu kan vi gøre vores forespørgsel lidt mere avanceret, så den tager parametre fra GraphQL-variabler:
query ($query: String, $pageSize: Int) {
search(
query: $query
pageSize: $pageSize
sort: FIELDS
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
Variabler:
{
"query": "+entityType:/Duck",
"pageSize": 10000
}
Her er et par ting at bemærke i denne forespørgsel:
query ($query: String, $pageSize: Int)- som du kan se, definerede vi en forespørgsel med parametre. Vi kan også give forespørgslen et navn:query searchEntities($query: String, $pageSize: Int)sort: FIELDS sortFields: {field: "id", direction: ASCENDING}- det er vigtigt at sortere efter et unikt felt for at få forudsigelige resultater, når du paginerer data.cursor- vi beder CluedIn om at returnere en speciel værdi, som vi kan sende med vores næste forespørgsel for at hente den næste side af resultater."pageSize": 10000- Som standard er sidestørrelsen 20, så hvis du har millioner af entiteter, får du kun de første20. Det er god praksis at sætte sidestørrelsen til den maksimalt tilladte værdi -10000, men der er situationer, hvor du kun vil hente et par entiteter fra toppen, og en forespørgsel med en mindre sidestørrelse vil være hurtigere.
CluedIn Python SDK
Du kan bruge ethvert programmeringssprog til at sende en GraphQL-request til CluedIn og få data tilbage. Lad os se, hvordan du kan gøre det i Python.
Først skal du installere den seneste version af CluedIn Python SDK:
%pip install cluedin
Lad os importere det sammen med Pandas (vi bruger Pandas til at indlæse data i DataFrames):
import pandas as pd
import cluedin
Du skal bruge et API token; du kan kopiere eller oprette et nyt ved at gå til "API Tokens" under "Administration" i CluedIn.
I mit tilfælde er CluedIn installeret på https://foobar.klimenko.dk/, så jeg skal initialisere en kontekst for min CluedIn-instans ved at angive org_name (foobar), domain (klimenko.dk) og access_token (det du kopierede fra CluedIn UI):
ctx = cluedin.Context.from_dict({
'domain': 'klimenko.dk',
'org_name': 'foobar',
'access_token': '{paste_your_token_here}'
})
Husker du GraphQL-forespørgslen, vi kørte fra CluedIn UI? Vi kan nu køre den fra Python-koden:
query = """
query searchEntities($query: String, $pageSize: Int) {
search(
query: $query
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 3
}
cluedin.gql.gql(ctx, query=query, variables=variables)
Resultatet er de tre øverste entiteter (fordi vi bruger sidestørrelse = 3 til demoformål), og vi får også en cursor, vi kan bruge til at hente den næste side:
{'data': {'search': {'cursor': 'ewAiAFAAYQBnAGUAIgA6ADEALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIALAAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIAXQB9AA==',
'entries': [{'id': '145afb55-4e78-5dad-b208-633b5b6d19cf',
'name': 'Donald Duck',
'entityType': '/Duck'},
{'id': '17bad60e-6782-5ae5-84bf-7efe05e78e58',
'name': 'Jake McDuck',
'entityType': '/Duck'},
{'id': '635383a9-9c75-5d61-8f2b-fe496fd82be7',
'name': 'Dewey Duck',
'entityType': '/Duck'}]}}}
Nu kan vi ændre vores kode lidt for at sende cursor som parameter:
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
cursor: $cursor
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 3
'cursor': 'ewAiAFAAYQBnAGUAIgA6ADEALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIALAAiADYAMwA1ADMAOAAzAGEAOQAtADkAYwA3ADUALQA1AGQANgAxAC0AOABmADIAYgAtAGYAZQA0ADkANgBmAGQAOAAyAGIAZQA3ACIAXQB9AA=='
}
cluedin.gql.gql(ctx, query=query, variables=variables)
Resultatet er de næste tre entiteter:
{'data': {'search': {'cursor': 'ewAiAFAAYQBnAGUAIgA6ADIALAAiAFAAYQBnAGUAUwBpAHoAZQAiADoAMwAsACIAQwBvAG0AcABvAHMAaQB0AGUAQQBmAHQAZQByACIAOgB7AH0ALAAiAFMAZQBhAHIAYwBoAEEAZgB0AGUAcgAiADoAWwAiADkAMwBiADkAMgA4ADMANQAtADkANgBmADIALQA1ADYAYQA5AC0AOQA4AGMAMAAtAGMAOAA0ADgAMgAzADYANQAyADEAYQA5ACIALAAiADkAMwBiADkAMgA4ADMANQAtADkANgBmADIALQA1ADYAYQA5AC0AOQA4AGMAMAAtAGMAOAA0ADgAMgAzADYANQAyADEAYQA5ACIAXQB9AA==',
'entries': [{'id': '6ae43a44-81b4-5fd7-9c7b-47cb24d407ea',
'name': 'Angus McDuck',
'entityType': '/Duck'},
{'id': '9353b703-13d8-59a1-886c-f40b95283c06',
'name': 'Hortense McDuck',
'entityType': '/Duck'},
{'id': '93b92835-96f2-56a9-98c0-c848236521a9',
'name': 'Matilda McDuck',
'entityType': '/Duck'}]}}}
Du forstår ideen.
Men hvad nu hvis du vil undgå manuelt at sende en ny cursor til hvert nyt kald? Brug bare cluedin.gql.entries-metoden, og den returnerer en Generator, som du kan konvertere til en liste eller bare iterere over, som du vil:
...
# her skal du bruge en mindre sidestørrelse
# hvis du ikke vil iterere til enden
variables = {
'query': '+entityType:/Duck',
'pageSize': 2
}
generator = cluedin.gql.entries(ctx, query=query, variables=variables)
print(next(generator))
print(next(generator))
Resultat:
{'id': '145afb55-4e78-5dad-b208-633b5b6d19cf', 'name': 'Donald Duck', 'entityType': '/Duck'}
{'id': '17bad60e-6782-5ae5-84bf-7efe05e78e58', 'name': 'Jake McDuck', 'entityType': '/Duck'}
Eller du kan indlæse alle entiteter i en DataFrame; i det tilfælde giver det mening at bruge den maksimale sidestørrelse (10000) for at reducere antallet af kald til serveren:
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
cursor: $cursor
pageSize: $pageSize
sort: FIELDS,
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
name
entityType
}
}
}
"""
variables = {
'query': '+entityType:/Duck',
'pageSize': 10_000
}
print(pd.DataFrame(cluedin.gql.entries(ctx, query=query, variables=variables)))
Resultat:
id name entityType
0 145afb55-4e78-5dad-b208-633b5b6d19cf Donald Duck /Duck
1 17bad60e-6782-5ae5-84bf-7efe05e78e58 Jake McDuck /Duck
2 635383a9-9c75-5d61-8f2b-fe496fd82be7 Dewey Duck /Duck
3 6ae43a44-81b4-5fd7-9c7b-47cb24d407ea Angus McDuck /Duck
4 9353b703-13d8-59a1-886c-f40b95283c06 Hortense McDuck /Duck
5 93b92835-96f2-56a9-98c0-c848236521a9 Matilda McDuck /Duck
6 a388a77d-7d43-51d1-87b2-efb4f854b5ad Fergus McDuck /Duck
7 b2fb05cb-e806-5088-955b-2ff3f9261236 Scrooge McDuck /Duck
8 b8fc5baf-b679-5e26-abb5-50ca77467992 Huey Duck /Duck
9 cd8fe1dd-5637-5037-931e-f8bf1a15c0b4 Della Duck /Duck
10 f5bf5d66-5698-515a-800e-9d778d916dcd Louie Duck /Duck
Fra CluedIn Python SDK 2.5.0 kan du reducere koden ovenfor til en enkelt linje og få næsten det samme resultat. Forskellen er, at den også returnerer alle codes og properties for entiteterne, men det er, hvad de fleste brugere gør alligevel, og du behøver ikke kopiere og indsætte den samme GraphQL-forespørgsel, hver gang du vil hente data:
# dette returnerer alle de forespurgte entiteter med alle properties og codes
print(pd.DataFrame(cluedin.gql.search(ctx, '+entityType:/Duck')))
Til sidst, hvis du kun vil have et udsnit af data, kan du bruge itertools.islice, men husk at sætte en mindre page_size for ikke at forespørge mere data, end du har brug for:
from itertools import islice
# henter en generator, der forespørger entiteter fra serveren tre ad gangen
gen = cluedin.gql.search(ctx, '+entityType:/Duck', page_size=3)
# wrap i en iterator, der stopper efter tre iterationer
iter = islice(gen, 3)
# konverter til DataFrame
df = pd.DataFrame(iter)
print(df)
Eller simpelthen:
pd.DataFrame(itertools.islice(cluedin.gql.search(ctx, '+entityType:/Duck', 3), 3))