Eksport af data fra CluedIn til Databricks eller Microsoft Fabric
I denne artikel indlæser vi data fra CluedIn til en Databricks-notebook, laver grundlæggende dataudforskning og transformation og gemmer data i en Delta Lake-tabel.
CluedIn
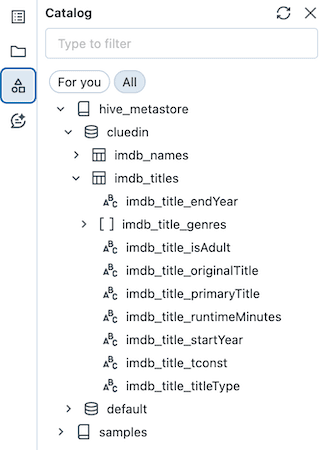
Vores CluedIn-instans har 601.222 entiteter af typen /IMDb/Title.
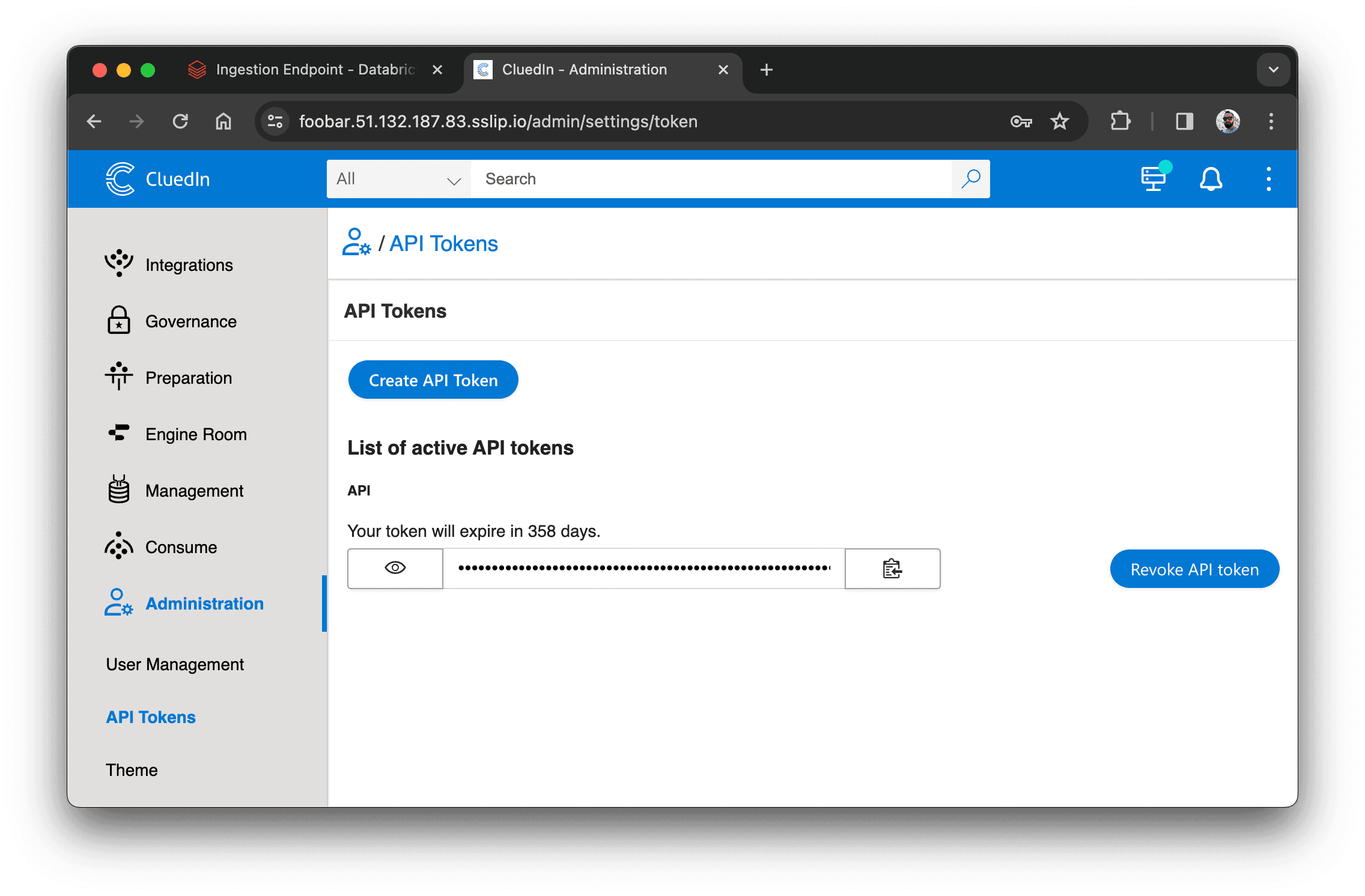
For at indlæse dem i Databricks skal vi oprette et API-token i CluedIn. Gå til Administration > API Tokens og opret et nyt token:
Databricks
Installer afhængigheder
For at forbinde til CluedIn API skal vi installere cluedin-biblioteket.
%pip install cluedin==2.2.0
Importer biblioteker
Vi skal bruge følgende biblioteker:
import pandas as pd
import matplotlib.pyplot as plt
import cluedin
Opret forbindelse til CluedIn
For at oprette forbindelse til CluedIn skal vi angive URL'en til vores CluedIn-instans og det API-token, vi oprettede tidligere:
# CluedIn URL: https://foobar.mycluedin.com/:
# - foobar is the organization's name
# - mycluedin.com is the domain name
cluedin_context = {
'domain': 'mycluedin.com',
'org_name': 'foobar',
'access_token': '(your token)'
}
Lad os nu hente noget data fra CluedIn. Vi henter kun én række for at se, hvilke data vi har:
# Create a CluedIn context object.
ctx = cluedin.Context.from_dict(cluedin_context)
# GraphQL query to pull data from CluedIn.
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
cursor: $cursor
pageSize: $pageSize
sort: FIELDS
sortFields: {field: "id", direction: ASCENDING}
) {
totalResults
cursor
entries {
id
name
entityType
properties
}
}
}
"""
# Fetch the first record from the `cluedin.gql.entries` generator.
next(cluedin.gql.entries(ctx, query, { 'query': 'entityType:/IMDb/Title', 'pageSize': 1 }))
Output:
{'id': '00001e32-9bae-53b9-a30f-cf30ed66c360',
'name': 'Murder, Money and a Dog',
'entityType': '/IMDb/Title',
'properties': {'attribute-type': '/Metadata/KeyValue',
'property-imdb.title.endYear': '\\N',
'property-imdb.title.genres': 'Comedy,Drama,Thriller',
'property-imdb.title.isAdult': '0',
'property-imdb.title.originalTitle': 'Murder, Money and a Dog',
'property-imdb.title.primaryTitle': 'Murder, Money and a Dog',
'property-imdb.title.runtimeMinutes': '65',
'property-imdb.title.startYear': '2010',
'property-imdb.title.tconst': 'tt1664719',
'property-imdb.title.titleType': 'movie'}}
Af hensyn til ydeevne og for at undgå kollisioner er det vigtigt at sortere resultaterne efter et unikt felt i GraphQL-forespørgslen. Entity ID fungerer fint:
sort: FIELDS
sortFields: {field: "id", direction: ASCENDING}
Lad os nu hente hele datasættet i en pandas DataFrame. Vi skal dog flade properties ud, fjerne unødvendige præfikser i property-navnene og erstatte punktummer med understreger for at gøre det kompatibelt med Spark-skemaet:
ctx = cluedin.Context.from_dict(cluedin_context)
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
sort: FIELDS
cursor: $cursor
pageSize: $pageSize
sortFields: {field: "id", direction: ASCENDING}
) {
totalResults
cursor
entries {
id
properties
}
}
}
"""
def flatten_properties(d):
for k, v in d['properties'].items():
if k == 'attribute-type':
continue
if k.startswith('property-'):
k = k[9:] # len('property-') == 9
k = k.replace('.', '_')
d[k] = v
del d['properties']
return d
df_titles = pd.DataFrame(
map(
flatten_properties,
cluedin.gql.entries(ctx, query, { 'query': 'entityType:/IMDb/Title', 'pageSize': 10_000 })))
df_titles.head()

En ting vi skal rette: lad os sætte DataFramens indeks til Entity Id:
df_titles.set_index('id', inplace=True)
df_titles.head()

Udforsk data
Lad os se, hvor mange film vi har per genre:
df_titles['imdb_title_genres'].str.split(',', expand=True).stack().value_counts().plot(kind='bar')
plt.title('Distribution of genres')
plt.xlabel('Genres')
plt.ylabel('Count')
plt.show()

Opret skema
Lad os nu oprette et skema for vores data (bemærk at imdb_title_genres er en streng, ikke et array, så vi skal splitte den):
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, ArrayType, IntegerType
from pyspark.sql.functions import split
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField('id', StringType(), True),
StructField('imdb_title_endYear', StringType(), True),
StructField('imdb_title_genres', ArrayType(StringType()), True),
StructField('imdb_title_isAdult', StringType(), True),
StructField('imdb_title_originalTitle', StringType(), True),
StructField('imdb_title_primaryTitle', StringType(), True),
StructField('imdb_title_runtimeMinutes', StringType(), True),
StructField('imdb_title_startYear', StringType(), True),
StructField('imdb_title_tconst', StringType(), True),
StructField('imdb_title_titleType', StringType(), True)
])
df_spark_titles = spark.createDataFrame(df_titles)
df_spark_titles = df_spark_titles.withColumn('imdb_title_genres', split(df_spark_titles.imdb_title_genres, ','))
spark.sql('CREATE DATABASE IF NOT EXISTS cluedin')
df_spark_titles.write.mode('overwrite').format('parquet').saveAsTable('cluedin.imdb_titles', schema=schema)
display(df_spark_titles)
Nu kan vi se vores data i kataloget: