
Brug af Pandas, Polars og DuckDB til den samme opgave
 (billedkilde: https://huggingface.co/alvarobartt/ghibli-characters-flux-lora)
(billedkilde: https://huggingface.co/alvarobartt/ghibli-characters-flux-lora)
Som regelmæssig Pandas-bruger er jeg normalt tilfreds med ydeevnen. Det kan håndtere millioner af rækker på minutter på min beskedne bærbare, og jeg har det fint med at vente. Men nye spændende værktøjer dukker op, og jeg er nysgerrig efter at prøve dem.
Jeg bruger normalt IMDb-datasæt til test og demoer, så i dag udførte jeg en velkendt rutine: indlæsning af hver TSV-fil (tab-separerede værdier) i en mappe og gemme den som Parquet. Den eneste forskel var, at jeg gjorde det med tre forskellige værktøjer: Pandas, Polars og DuckDB.
IMDb's TSV-filer har deres særheder:
- Selvom de for det meste ligner normale CSV-filer, er separatoren en tabulator i stedet for et komma.
- Numeriske værdier (årstal) er blandet med '\N'-værdier, som vi kan erstatte med null eller ændre kolonnernes typer til streng (jeg vælger den anden mulighed).
- Der optræder dobbelte anførselstegn i kolonneværdier, så vi skal eksplicit ignorere dem.
Pandas
Jeg starter med Pandas som det mest kendte værktøj. En simpel version af koden ser sådan ud:
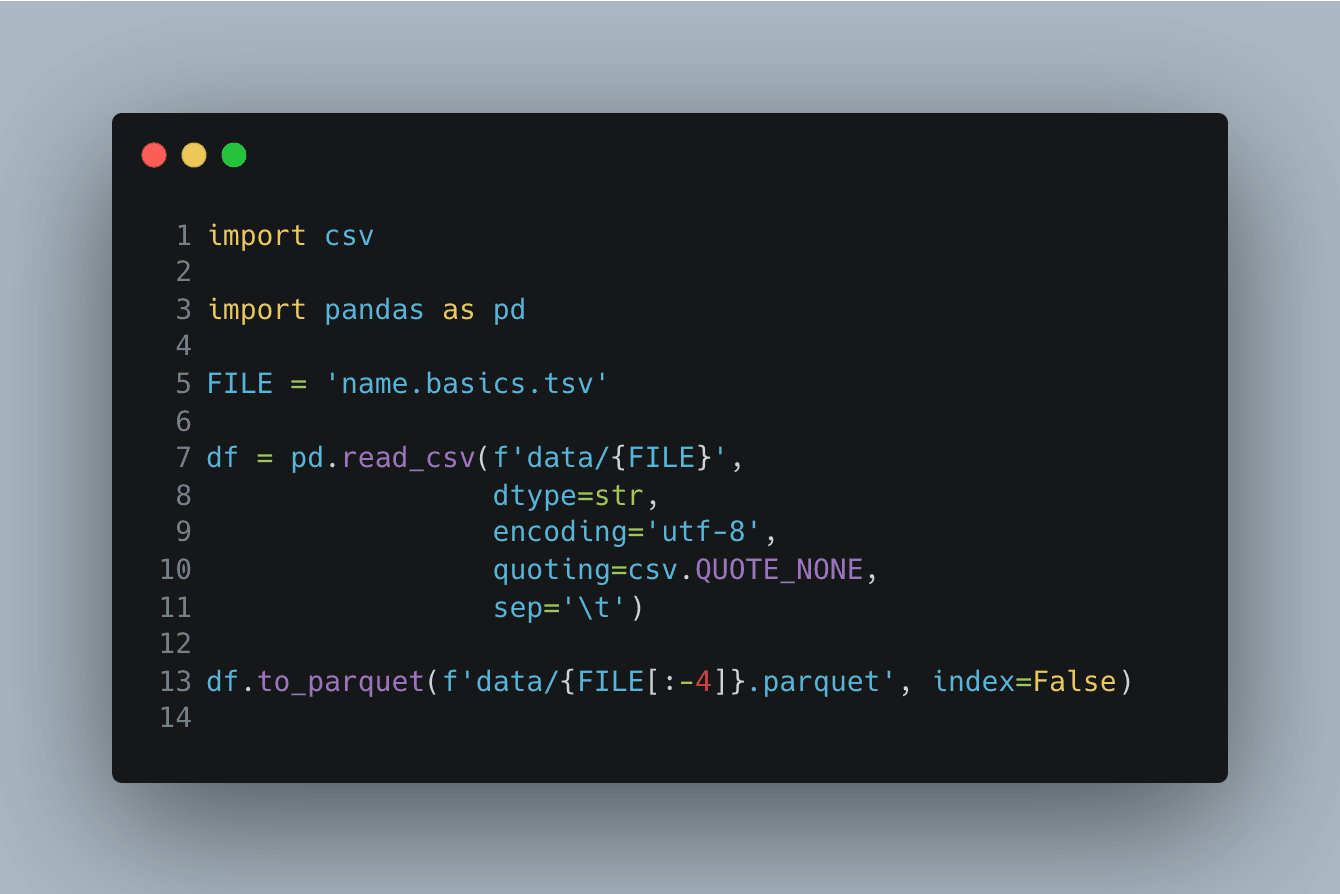
names.basic.tsv indeholder 13.774.705 rækker, og det tager 15-20 sekunder
for min fire år gamle Apple MacBook M1 at køre scriptet.
Polars
Lad os nu se på Polars.
Polars' API er intuitivt efter Pandas, og jeg havde ingen problemer med at bruge det.
Koden blev lidt længere, fordi der ikke var nogen dtype-parameter i read_csv-metoden
til at overskrive alle kolonnetyper på én gang, men det er ikke et problem:
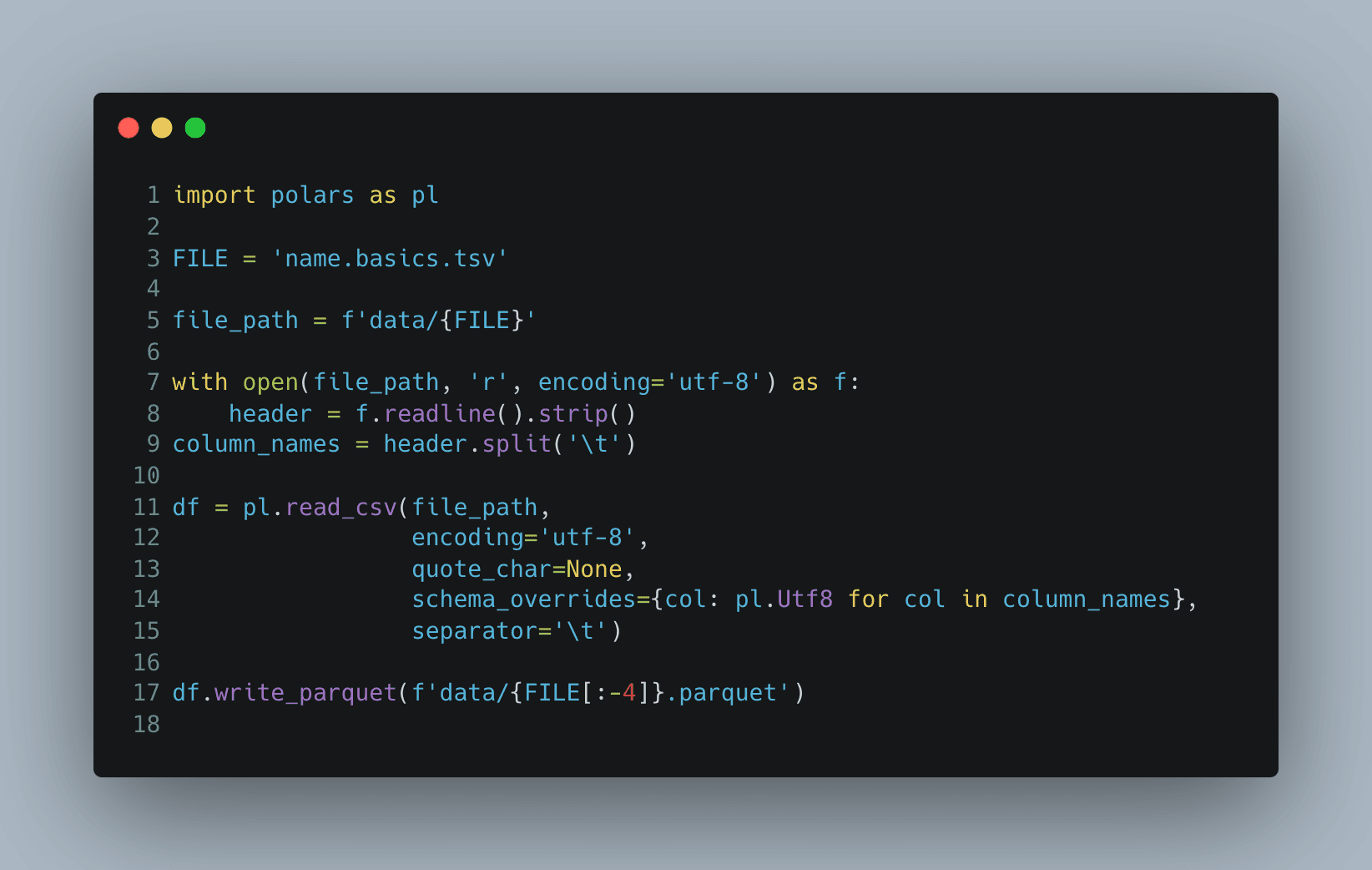
Denne kode kører på 14-15 sekunder.
DuckDB
Med DuckDB kan man bruge SQL:
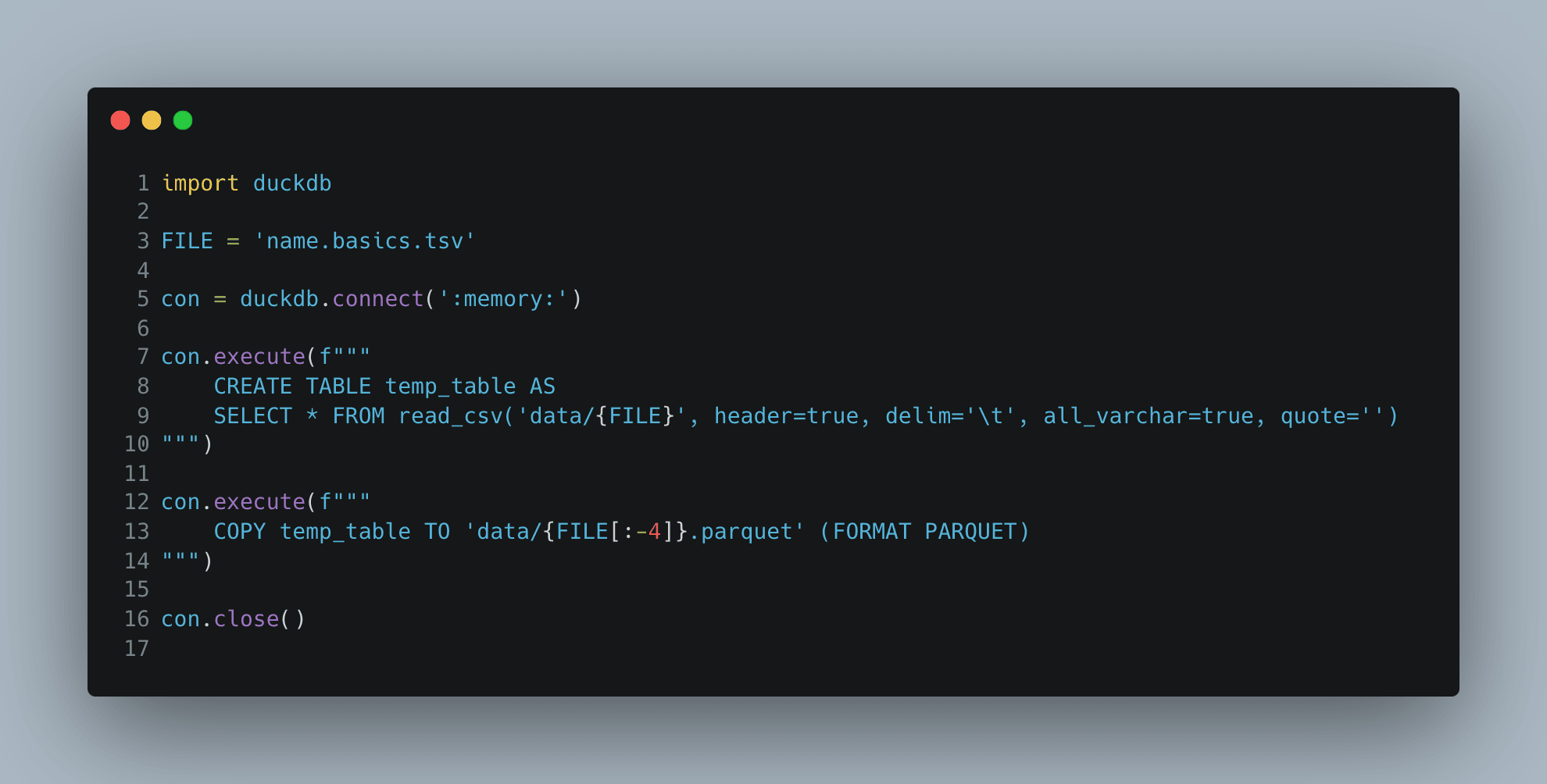
Alternativt kan man bruge SDK-metoderne:
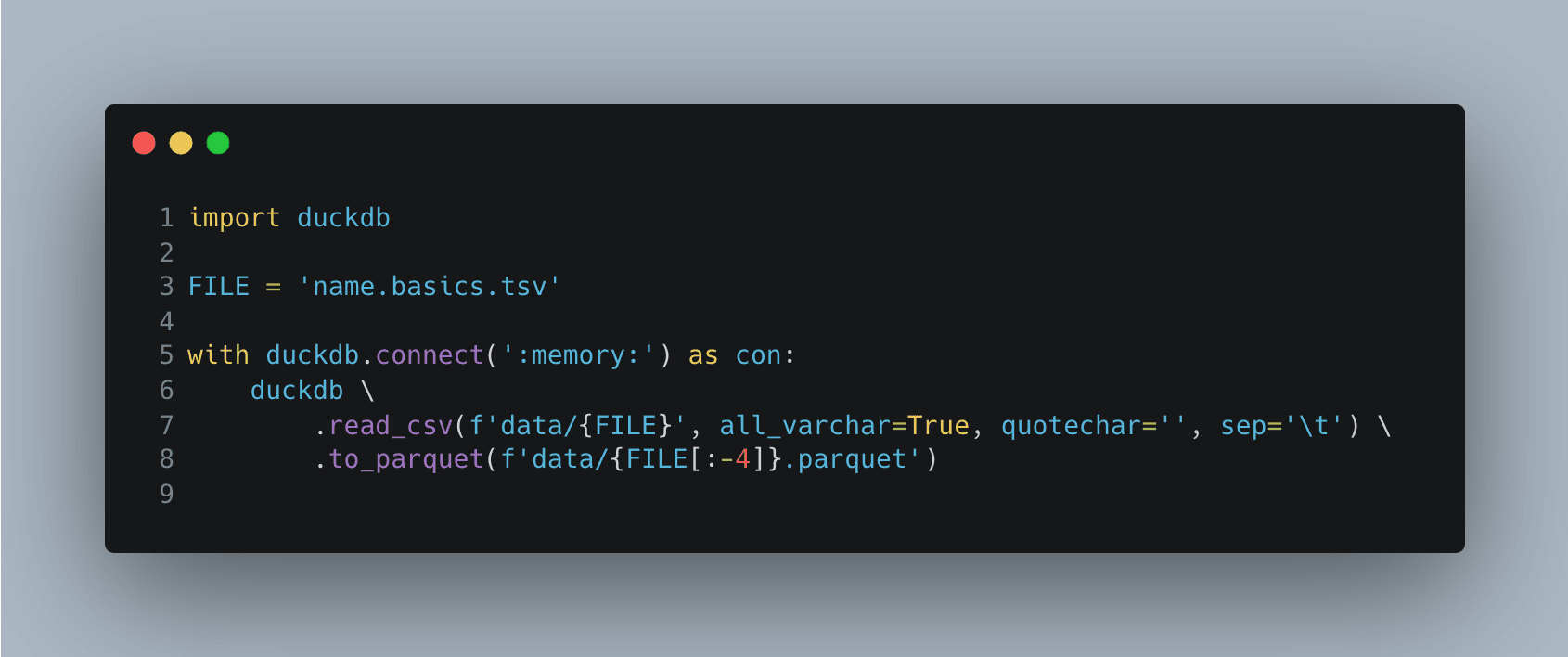
I det sidste eksempel oprettes tabellen ikke: duckdb.read_csv
returnerer et lazy-objekt, der først itereres, når vi kalder .to_parquet,
hvilket gør kørslen endnu hurtigere: omkring seks sekunder
hvis vi opretter en tabel og fire sekunder hvis vi ikke gør.
DuckDB's API er til tider overraskende. For eksempel har read_csv
sep- og delim-parametre til det samme,
hvilket er forvirrende, når man scroller gennem metodens parametre,
især fordi Python SDK'et ikke har docstrings. Når noget går galt,
ser man et output som dette:
delimiter = (Set By User)
Så man har sep, delim, men det hedder delimiter i fejlmeddelelsen.
Men der er ikke noget at klage seriøst over — API'et er rigt, og værktøjet fungerer fremragende.
Indlæsning af alle IMDb-datasæt
I næste trin forberedte jeg scripts til at indlæse hver IMDb TSV-fil i en mappe og gemme dem som Parquet. Jeg vil ikke overlæsse denne artikel med kode, men du kan finde scripts her: https://github.com/romaklimenko/imdb
Ydeevneresultaterne var overraskende. Jeg forventede, at Polars ville klare opgaven hurtigere end Pandas, men det var markant langsommere. De gennemsnitlige køretider for hvert script er:
- Pandas:
196sekunder - Polars:
257sekunder - DuckDB:
46sekunder
DuckDB er langt foran de andre, men Pandas og Polars vinder og taber i forskellige kategorier.
For eksempel har title.principals.tsv 87.769.634 rækker:
- Pandas: indlæs TSV -
49sekunder, skriv til Parquet -32sekunder. - Polars: indlæs TSV -
140sekunder, skriv til Parquet -10sekunder.
Men tag title.basics.tsv, som har 11.054.773 rækker:
- Pandas: indlæs TSV -
14sekunder, skriv til Parquet -6sekunder. - Polars: indlæs TSV -
6sekunder, skriv til Parquet -4sekunder.
Konklusion
At benchmarke værktøjer på et enkelt scenarie er en utaknemmelig opgave. Selvfølgelig er der tilfælde, hvor Polars er hurtigere end Pandas: https://duckdblabs.github.io/db-benchmark/, men forskellen er ikke så tydelig i "små" datasæt med flere millioner rækker.
Jeg håber, at disse produkter finder deres niche, da Pandas' og Polars' API'er ligner hinanden.
DuckDB viser imponerende ydeevne og løser mange problemer, hvor jeg ellers ville være nødt til at køre en databaseserver. Dets API er ikke helt poleret endnu, men jeg kan tolerere det for dets gode egenskaber.
Jeg glæder mig til at bruge disse nye værktøjer i mine daglige opgaver.