
Brug af CluedIn GraphQL API til at automatisere UI-handlinger
CluedIn opfordrer som Master Data Management-system brugerne til at arbejde med data via UI og en low-code tilgang. Du kan gennemføre en fuld datacyklus fra indtagelse af data i CluedIn til datamodellering, transformation, rensning, berigelse, deduplikering og eksport uden at skrive en eneste linje kode.
Der er dog situationer, hvor automatisering og simpel scripting kan redde dagen. Og på samme måde som vi kan frigøre forretningsbrugere fra at skulle håndtere IT og kode, kan vi frigøre dem fra gentagne handlinger i brugergrænsefladen, når man for eksempel implementerer en CI/CD-pipeline mellem udviklings-, staging- og produktionsinstanser.
I denne artikel implementerer vi grundlæggende automatisering uden at vide for meget om det på forhånd. Lad os starte med det faktum, at CluedIn UI kommunikerer med serveren via GraphQL API.
To GraphQL API-endpoints
CluedIn tilbyder to GraphQL API-endpoints:
/api/api/graphql- endpointet der bruges til at forespørge data./graphql- endpointet til UI-interaktioner.
Autentificering
CluedIn bruger JWT token-baseret autorisation.
Der er to slags tokens i CluedIn: API Tokens og Access Tokens.
API Tokens bruges til at udtrække eller indlæse data fra og ind i CluedIn. Du kan oprette eller kopiere et API Token fra Administration -> API Tokens.
Access Tokens genereres, når du logger ind i CluedIn som bruger.
Du skal bruge et API Token for at anvende /api/api/graphql-endpointet.
/graphql-endpointet accepterer kun Access Tokens, så du skal logge ind med din e-mail og adgangskode for at få et.
Hvis du bruger et værktøj som Postman, er her en artikel, der forklarer, hvordan du kan få dit Access Token: "Using Postman to interact with CluedIn API".
Hvis du planlægger at forespørge data med Python SDK, dækker en anden artikel dette emne: "Search Entities with CluedIn Python SDK".
Udforskning af GraphQL API
I denne artikel udforsker vi et use case med automatisering af de handlinger, du normalt udfører i UI, ved hjælp af CluedIn GraphQL API og CluedIn Python SDK.
Lad os bruge et simpelt eksempel: Du vil automatisere oprettelsen af Vocabularies. Du kan gøre det fra CluedIn UI, men du foretrækker en automatiseret tilgang til at synkronisere Vocabularies fra et andet sted.
Det første du kan gøre er at oprette et test-Vocabulary i en browser og se, hvordan API-kaldene ser ud. Du kan gøre det med Network-fanen eller med hjælp fra GraphQL Network Inspector (bedre).
Lad os prøve begge tilgange. Først går jeg til UI og opretter et test-CluedIn Vocabulary, mens jeg har min Network-fane åben:
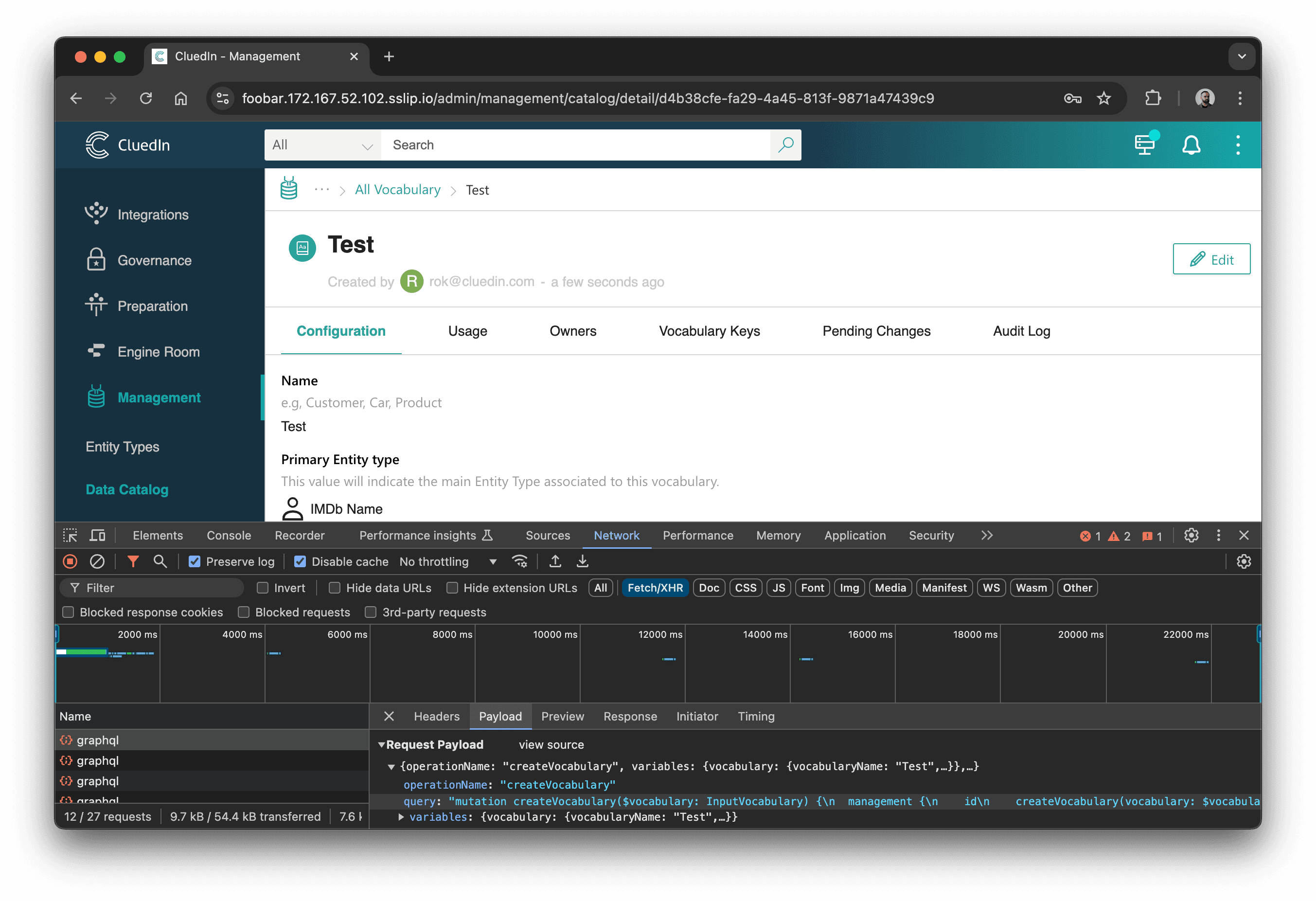
Når jeg nu inspicerer GraphQL-forespørgsler, kan jeg se createVocabulary mutation-kaldet:
Det er endnu nemmere at finde det rigtige kald med GraphQL Network Inspector:
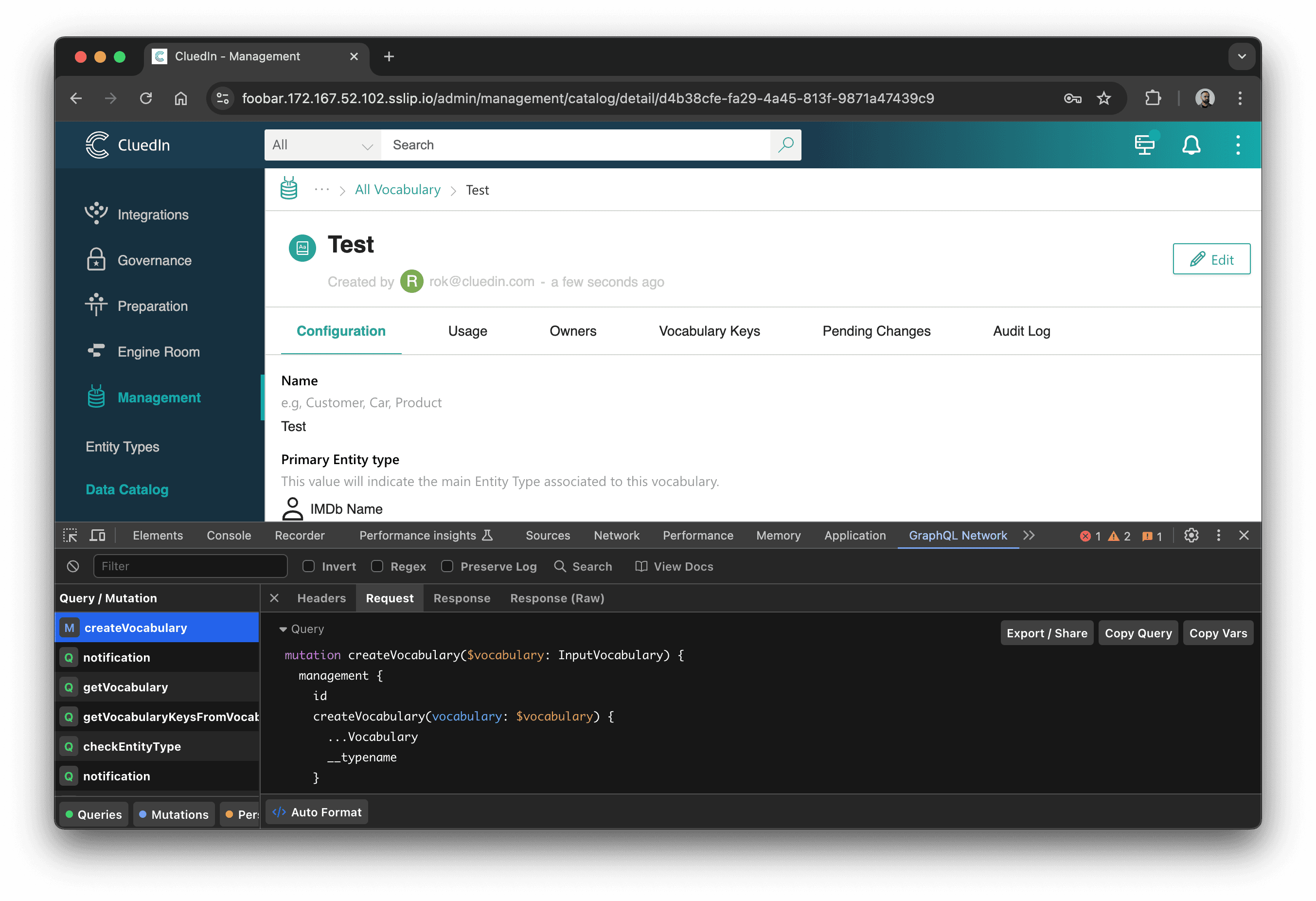
Uanset hvordan vi fandt det, kan vi nu kopiere GraphQL-forespørgslen:
mutation createVocabulary($vocabulary: InputVocabulary) {
management {
id
createVocabulary(vocabulary: $vocabulary) {
...Vocabulary
__typename
}
__typename
}
}
fragment Vocabulary on Vocabulary {
vocabularyId
vocabularyName
keyPrefix
isCluedInCore
entityTypeConfiguration {
icon
entityType
displayName
__typename
}
isDynamic
isProvider
isActive
grouping
createdAt
providerId
description
connector {
id
name
about
icon
__typename
}
__typename
}
Og variablerne:
{
"vocabulary": {
"vocabularyName": "Test",
"entityTypeConfiguration": {
"new": false,
"icon": "Profile",
"entityType": "/IMDb/Name",
"displayName": "IMDb Name"
},
"providerId": "",
"keyPrefix": "test",
"description": ""
}
}
Python SDK
Nu kan vi bruge CluedIn Python SDK til at oprette et Vocabulary.
Først opretter jeg en fil med mine CluedIn-legitimationsoplysninger. Du kan også angive dem via environment-variabler:
{
"domain": "172.167.52.102.sslip.io",
"org_name": "foobar",
"user_email": "admin@foobar.com",
"user_password": "mysecretpassword"
}
Derefter installerer jeg CluedIn Python SDK:
%pip install cluedin
Herefter skal jeg "logge ind" i CluedIn for at få Access Token:
import cluedin
ctx = cluedin.Context.from_json_file('cluedin.json')
ctx.get_token()
ctx-objektet indeholder nu Access Token, og jeg kan bruge det til at oprette et Vocabulary:
def create_vocabulary(ctx, name, prefix):
query = """
mutation createVocabulary($vocabulary: InputVocabulary) {
management {
id
createVocabulary(vocabulary: $vocabulary) {
...Vocabulary
}
}
}
fragment Vocabulary on Vocabulary {
vocabularyId
vocabularyName
keyPrefix
entityTypeConfiguration {
icon
entityType
displayName
}
providerId
description
}
"""
variables = {
"vocabulary": {
"vocabularyName": name,
"entityTypeConfiguration": {
"new": False,
"icon": "Profile",
"entityType": "/IMDb/Name",
"displayName": "IMDb Name"
},
"providerId": "",
"keyPrefix": prefix,
"description": ""
}
}
return cluedin.gql.org_gql(ctx, query, variables)
Lad os teste det:
print(create_vocabulary(ctx, 'Foo Bar', 'foo.bar'))
Output:
{
"data": {
"management": {
"id": "management",
"createVocabulary": {
"vocabularyId": "e4528e92-f4ad-406a-aeab-756acc20fd01",
"vocabularyName": "Foo Bar",
"keyPrefix": "foo.bar",
"entityTypeConfiguration": {
"icon": "Profile",
"entityType": "/IMDb/Name",
"displayName": "IMDb Name"
},
"providerId": null,
"description": ""
}
}
}
}
Tjek brugergrænsefladen:
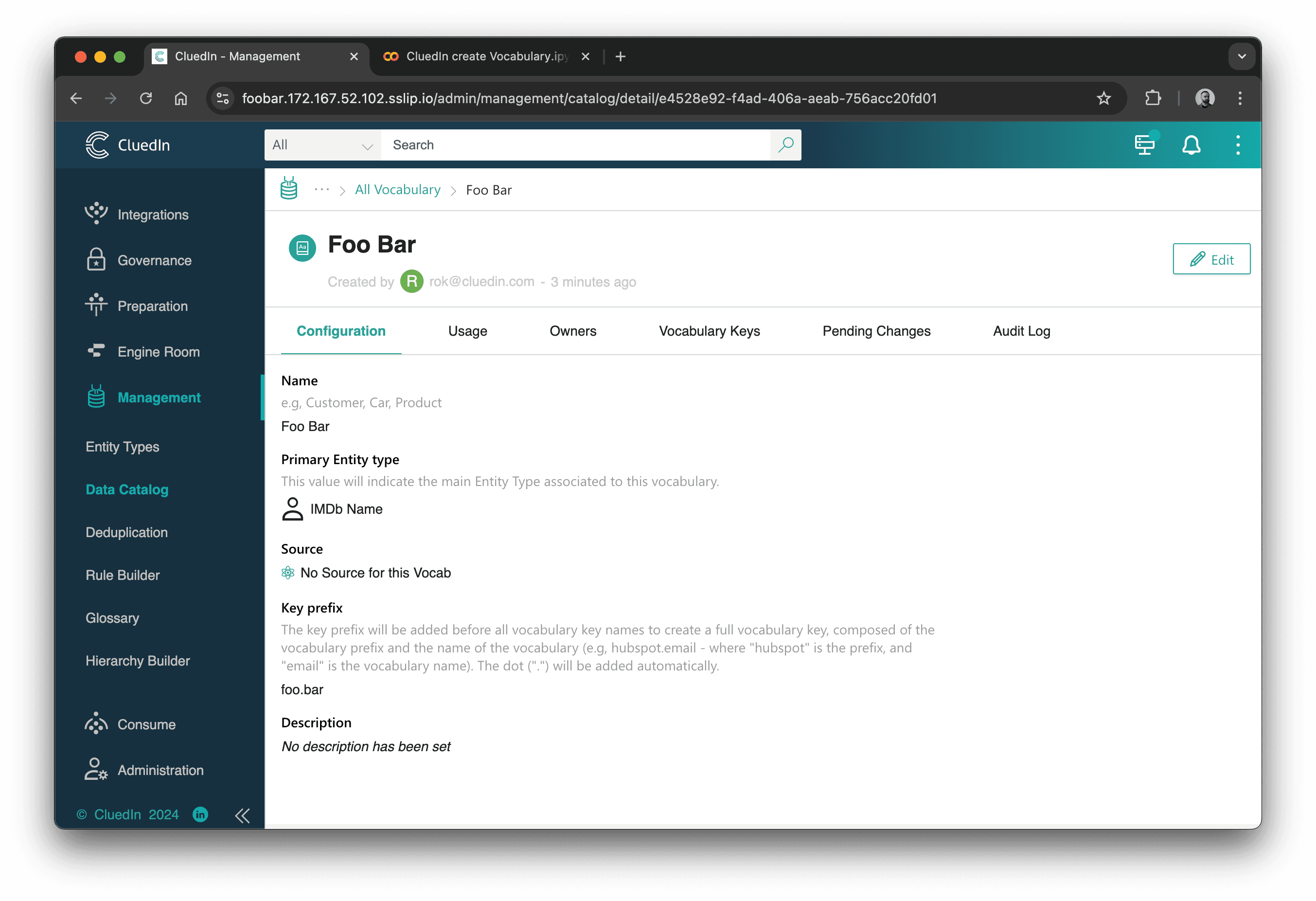
Og det er det! Her er et par eksempler, jeg har brugt i rigtige projekter:
- Opret manglende Vocabularies og keys for en given Entity: https://gist.github.com/romaklimenko/a203c3ef63b4106304e62f6f816d7e25
- Udforsk en CluedIn Entitys Data Parts for at fejlfinde overmerging: https://gist.github.com/romaklimenko/d5a07dde12e8f215d69131de47976d7d